Stable Diffusion (img2img) + Hugging Face 画像を元に自動お絵かきAI 簡単に使ってみた
前回は、文字(prompt)を元にした自動お絵かきAIの記事を書きました。
今回は、画像を元にした自動お絵かきAI(img2img)の記事を書きたい思います。
前回の記事の中から、必要な部分のみ再度記述して、画像を元にした自動お絵かきAI(img2img)の手順について書いていきます。
Hugging Face
アクセストークンを取得する
Hugging Faceで提供しているライブラリにアクセスするためのトークンを取得します。
無料でできますので、実施しましょう。
Hugging Faceにアクセスし、右上の「Sign Up」を選択します。
登録すると、メールでの認証確認がありますので、忘れずに行いましょう。
プロフィールページから、「Access Token」に移動し、「New Token」ボタンを押します。
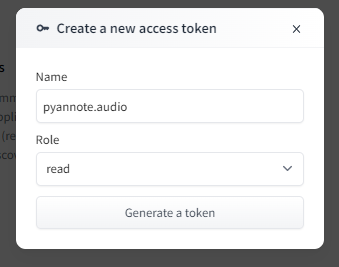
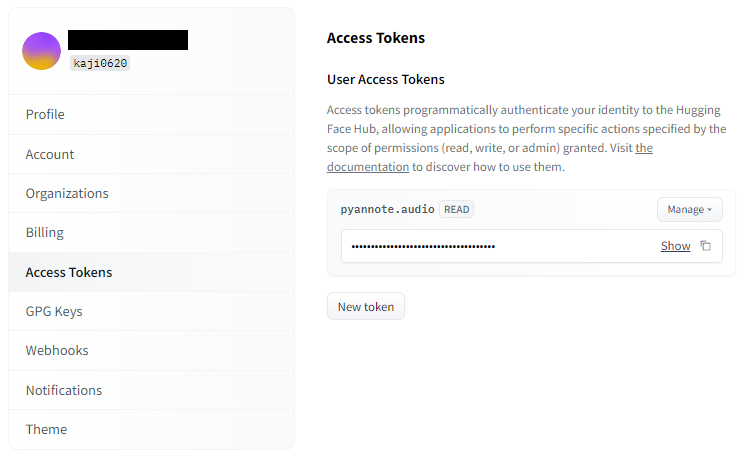
後ほど、pythonのコード内でHugging Faceにアクセスする時に使用します。
本トークンは、他人に知られないように十分に注意して取り扱ってください。
自動お絵かきAI(img2img)の実行
Hugging Faceのモデル一覧のページにアクセスすると、様々なモデルを見ることができます。
今回もGoogle Colaboratoryを使用して、コードを記載していきたいと思います。
最初に、「編集」→「ノートブックの設定」から、
ハードウェアアクセラレートを「GPU」に設定しましょう。
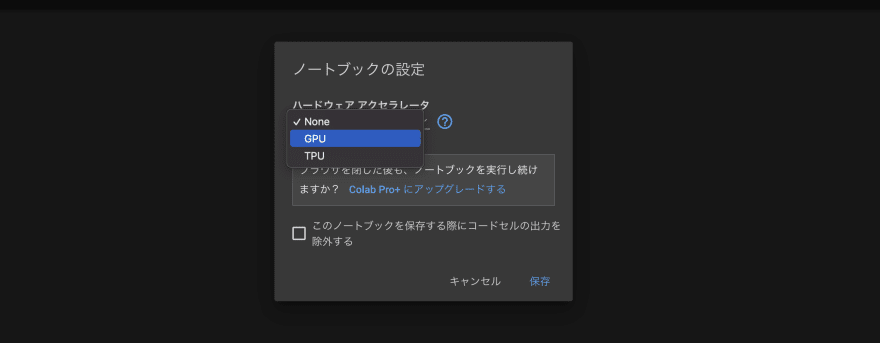
以下のコマンドを入力し、Shift+Enterを押して実行しましょう。
GPUの情報が出てくれば、正常に設定変更できています。
!nvidia-smi続けて、コードを記載していきます。
今回のモデルは「CompVis/stable-diffusion-v1-4」です。
!pip install diffusers transformers scipy ftfy
from diffusers import StableDiffusionImg2ImgPipeline
import torch
AuthToken="(取得したアクセストークンを入力)"# モデル:Stable Diffusion V1.4 を使用する場合
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, use_auth_token=AuthToken).to(device)実行後に、「accelerateを入れた方が良いよ」「サンプルサイズ設定を小さくした方が良いよ」など
メッセージが出ますが、よく分かっていないのでそのまま続行しています。
後々、対処方法が分かったら追記したいと思います。
参考とする入力画像は「いらすとや」さんより頂きました。「sample.png」とします。
Google Colaboratoryの左側のファイル一覧にアップロードして読み込めるようにしておきましょう。
※線画などのラフ画では不要ですが、イラストのような画像の場合は、背景の部分を、
PNG形式であれば透過設定、JPG形式であれば黒色にしておく方が成功率が高いです。

参考とする入力画像を読み込みます。
from PIL import Image
init_image = Image.open("sample.png").convert("RGB")
init_image = init_image.resize((512, 512))
init_image画像の生成について細かくパラメータを設定したい場合、以下の通りです。
- Prompt
この部分に任意の文字列(英語)を入力することで、好きな絵を出力させることができます。 - Image
参考とする入力画像を入力します。 - Mask_image
参考とする入力画像と同じサイズの白黒画像を入力すると、
黒い部分は修正を加えないようにすることが可能。 - Strength
参考とする入力画像へのpromptの影響度(0~1)。デフォルト=0.8。
0にすると影響なし(入力画像のまま)になる。 - Guidance Scale
入力されたプロンプト(呪文)への忠実度を制御するためのパラメータ(1~30)。
デフォルト値=7.5。1が設定された場合、プロンプトは完全に無視。
5~10程度が、出力画像を見ているとバランスが良い。 - Num Inference Steps
画像をどれくらい精細に描画するかを決めるパラメータ
設定値が高いほど高精細な画像なるが、生成時間が長くなる。
デフォルト値=50。100~120程度が時間、精度を考慮するとバランスが良い。
※実行時にはStrengthとの掛け算になるので注意 - Seed
通常ランダムで設定されるSeed値を固定することで、同じ画像を再現することが可能。
デフォルト値=ランダム - width・height
出力画像の幅・高さの設定。デフォルト値=512
from datetime import datetime
prompt = "a photo of, pizza"
#描画する回数を設定
num_images = 1
#イラスト生成
for i in range(num_images):
# seedを固定しない場合
image = pipe(prompt, image=init_image, strength=0.8, guidance_scale=7.5, num_inference_steps=50).images[0]
# seedを固定する場合
#generator = torch.Generator(device).manual_seed(2000)
#image = pipe(prompt, image=init_image, strength=0.8, guidance_scale=7.5, num_inference_steps=50, generator=generator).images[0]
#生成日時をファイル名にして保存
date = datetime.now().strftime("%Y%m%d_%H%M%S")
path = date + ".png"
image.save(path)
from IPython.display import Image,display_png
display_png(Image(path))以下のような画像が出力されればOKです。
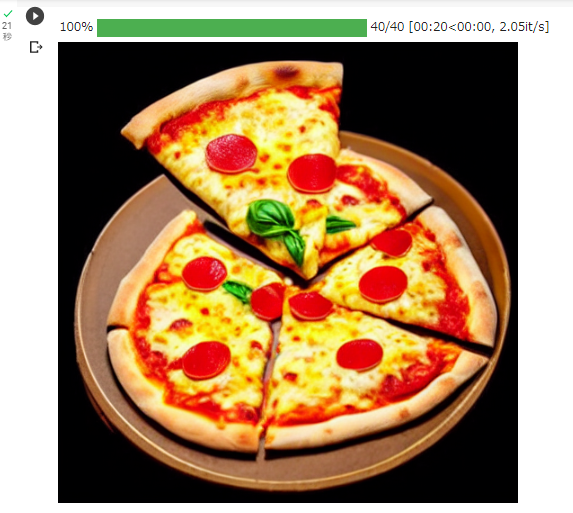
この記事の作成時、最初は入力画像のサイズ変更を適当に (256, 256) にしており、
何度も色々やってみたけど、ピザとは程遠い画像が永遠と出力されていました。
諦めようかと思っていた頃、色々と数字を変更した中で (512, 512) にした時、
いとも・すんなりと・あっさりと、あの画像がでました。マジか。。。
(出力画像よりサイズが大きくないとダメ?? 出力画像と同じサイズでないとダメ??)
とりあえず、ここまで。
※メモ
「StableDiffusionImg2ImgPipeline」で「Ctrl+右クリック」からソースに移動
「run_safety_checker」関数内を「has_nsfw_concept = None」だけにして保存。再インポート。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日