中国発のLLM Xwin-LM ローカル環境で動かしてみた
2023年10月31日
2023年11月8日
2023年9月にOpenAIの生成AI「GPT-4」を上回る性能をうたってリリースされたXwin-LM。
中国科学院や清華大学の研究者らが開発したようです。ロゴ格好よし。

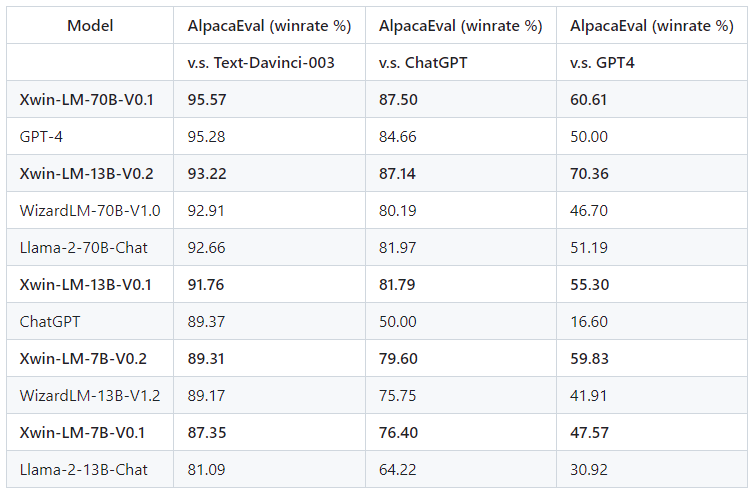
GitHub、Hugging Face上で公開されているので、実際に使って試してみました。
Google Colabolatoryの無料枠では実行できそうになかったので、メモリ64GB積んだPCを用いて、
Ctranslate2を用いてコンバートし、GPUなしで実行してみました。
早速、下記に必要なライブラリのインストールと、コンバートするためのコマンドを記載します。
!pip install ctranslate2
!pip install sentencepiece transformers
!ct2-transformers-converter \
--model Xwin-LM/Xwin-LM-7B-V0.2 \
--quantization int8 \
--output_dir ./Xwin-LM-7B-V0.2 \
--low_cpu_mem_usage※「You are using the default legacy behaviour of the <class …」とメッセージが出ますが、
とりあえず「–output_dir」で指定したフォルダに、3個のファイルが問題なく作成されているはずです。
(config.json、model.bin、vocabulary.txt)
下記のtokenizerオプションに「legacy=False」を入れることで、モデル実行時には上記表示は回避できます。
実行するプログラムは下記の通り。
Hugging Face上のサンプルを少し変えて、日本語で回答がもらえるようにしてみました。
無事に動いております。
import ctranslate2
import transformers
import torch
model_name = "Xwin-LM/Xwin-LM-7B-V0.2"
ct2_model = "./Xwin-LM-7B-V0.2"
# ジェネレーターとトークナイザーの準備
device = "cuda" if torch.cuda.is_available() else "cpu"
generator = ctranslate2.Generator(ct2_model, device=device)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, use_fast=False, legacy=False)
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? Please say Japanese."
"ASSISTANT:"
)
tokens = tokenizer.convert_ids_to_tokens(
tokenizer.encode(prompt, add_special_tokens=False, truncation=True, max_length=128)
)
results = generator.generate_batch(
[tokens],
sampling_topk=10,
sampling_temperature=0.7,
include_prompt_in_result=False,
)
text = tokenizer.decode(results[0].sequences_ids[0])
print(text)こんにちは!どのようなお手伝いができますか?日本語でお話しができますので、どんな質問や相談があってもお気軽にお聞かせください。 (Konnichiwa! What kind of help can I give you? I can speak Japanese, so feel free to ask any questions or share your concerns. )
備忘録の意味合い強く、短いですが載せておきます。
Ctranslate2のお陰で、様々なモデルをGPUなしのローカル環境でお試しで使えるのは、大変助かりますね。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日