ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた
2023年4月30日
Whisperについて、高速化したfast-whisperについては、過去に記事を書いてきました。
今回は、ReazonSpeech(約19,000時間の放送音声からなるラベル付き日本語音声コーパス)を用いて文字起こしをして行きたいと思います。
ちなみに、精度に関してはWhisper Large-v2よりも良いとのことです。しかも、軽いです。
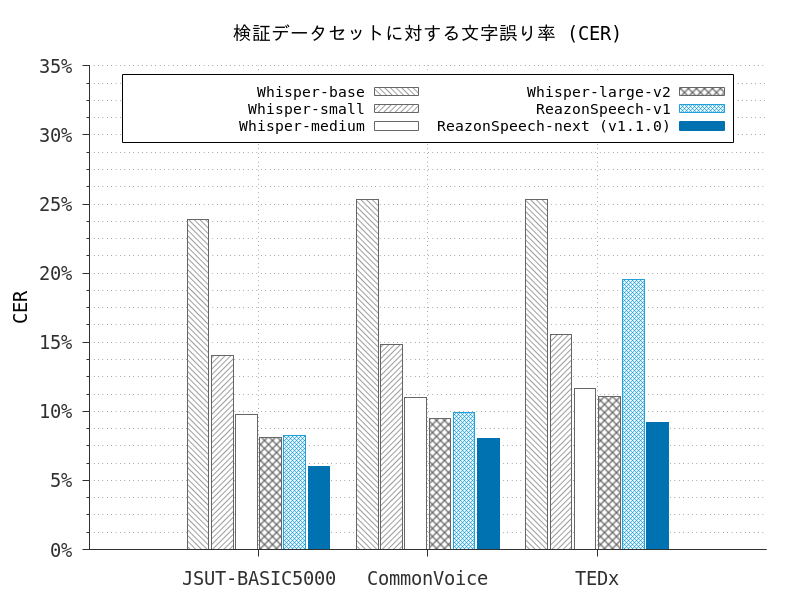
ReazonSpeechを動かしてみる
Google Colaboratory上で実行してきます。ハードウェアアクセラレートを「GPU」に設定するのをお忘れなく。
早速、インストールしてみましょう。少し時間がかかりますが、待ちましょう。
!pip install git+https://github.com/reazon-research/reazonspeechインポートの設定、モデルを読み込みをします。
import torch
from espnet2.bin.asr_inference import Speech2Text
import librosa
import reazonspeech as rs
device = "cuda" if torch.cuda.is_available() else "cpu"
speech2text = Speech2Text.from_pretrained(
"reazon-research/reazonspeech-espnet-next",
beam_size=5,
batch_size=0,
device=device
)文字コード環境がUTF-8でないためにエラーが起きることがあります。以下のコードを実行しましょう。
import locale
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencoding以前の動画の半自動作成の記事で作成したYoutube動画を音声形式にしてダウンロードします。
!pip install yt-dlp
!rm input.mp3
!yt-dlp -x --audio-format mp3 https://youtu.be/1XQVbMz4j-0 -o "input.mp3"自動書き起こしを実行します。
file_name="input.mp3"
SAMPLE_RATE = 16000
speech, sample_rate = librosa.load(file_name, sr=SAMPLE_RATE)
for cap in rs.transcribe(speech, speech2text):
start_time = cap.start_seconds
end_time = cap.end_seconds
text = cap.text
print("[%.2fs -> %.2fs] %s" % (start_time, end_time, text))一部書き起こしができていなかったり、文章の区切りがいまいちですが、ほぼ正確です。

非常に軽いので、ローカル環境でも容易に動かせるのは魅力です。
精度・文章の区切りの良さを考えると、Whisperの方が良いように感じます。
とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日