Whisper 音声・動画の自動書き起こしAIを無料で、簡単に使おう
OpenAIが公開しているWhisper(音声・動画の自動書き起こしAI)を
簡単に試す方法がありましたので、記録として残します。
副業の「文字起こし」「テープ起こし」「動画のテロップ作成」など
非常に有効な武器となりそうなので、身に付けるべく。
動かしてみよう
自分のローカルのパソコンに、pythonの環境を用意して実行もしましたが、
圧倒的にGoogle Colaboratoryで実行する方が簡単でした。
しかも、Google Colaboratoryの利用は、1日の使用量に制限はありますが無料です。
Google Colaboratoryにアクセス
Googleアカウントを取得している前提ですが、
Google Colaboratoryにアクセスします。「ノートブックの新規作成」を選択します。
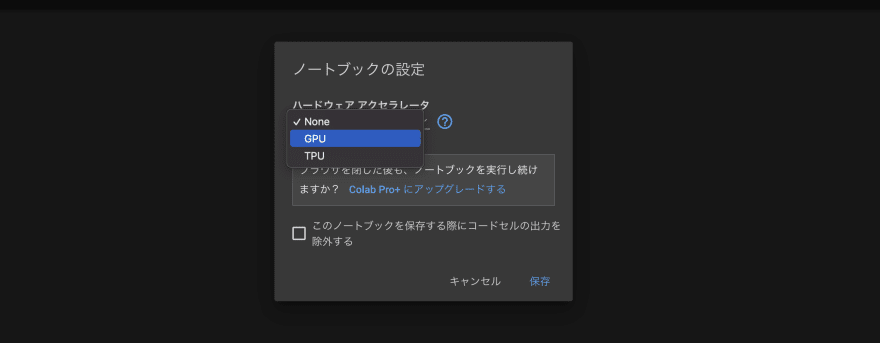
最初に、「編集」→「ノートブックの設定」から、
ハードウェアアクセラレートを「GPU」に設定しましょう。
以下のコマンドを入力し、Shift+Enterを押して実行しましょう。
GPUの情報が出てくれば、正常に設定変更できています。
!nvidia-smiGoogleドライブへのアクセス許可
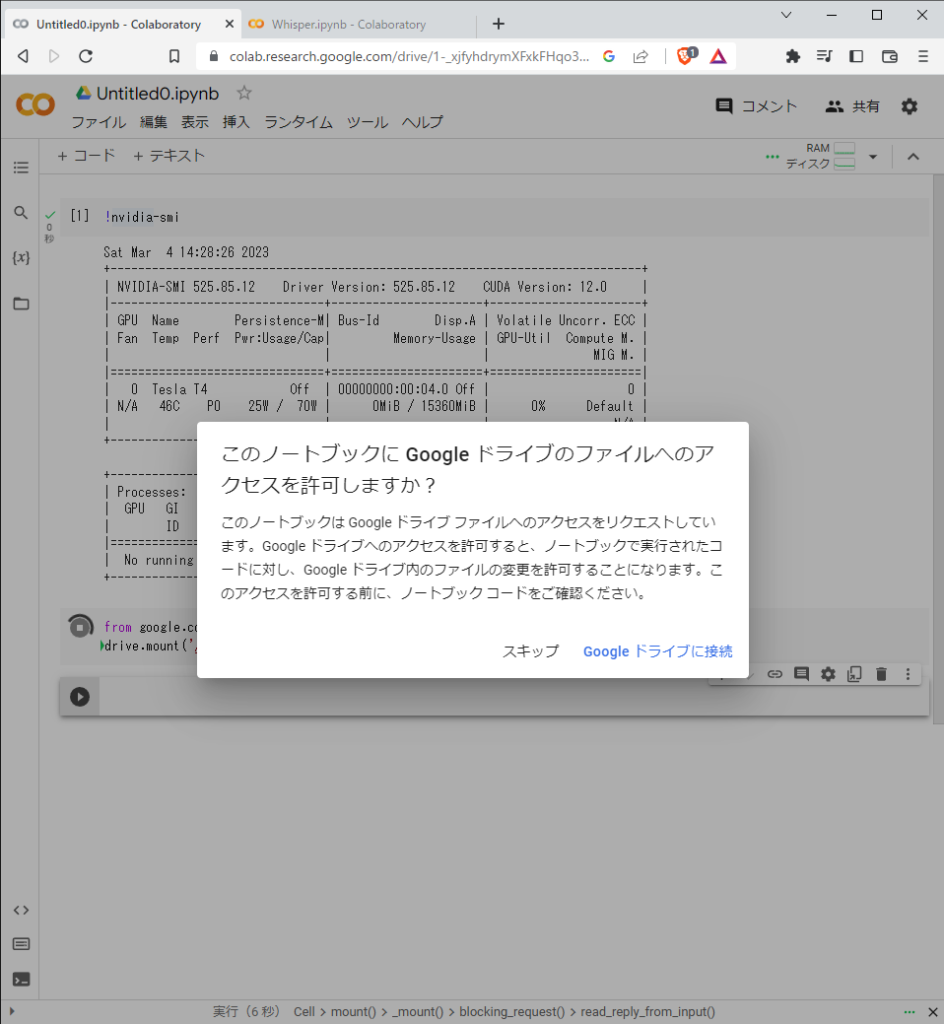
読み込ませる音声ファイルをGoogleドライブ経由で取得できるように、
マウント(ドライブの認識)をさせます。
以下のコードを入力し、Shift+Enterを押して実行しましょう。
from google.colab import drive
drive.mount('/content/drive')Googleドライブへの接続を許可してください。
「Mounted at /content/drive」と出れば、正常に完了しています。
Whisperのインストール
必要なパッケージのインストールと、使用するモデルのサイズを指定します。
以下のコードを入力し、Shift+Enterを押して実行しましょう。
! pip install git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("medium")modelの値は、以下の通りです。
medium, largeのどちらかが現実的な選択肢です。それ以下だと手直しが大変です。
※ローカルの非力なパソコンでは、逆にsmall, baseあたりでないと動きません。

Googleドライブに音声ファイルを置く
書き起こしたい音声ファイルをGoogleドライブのマイドライブ直下に保存します。
続けて、以下のコードを入力し、Shift+Enterを押して実行しましょう。
※ファイル名は適宜修正してください。
以下にサンプルファイル「g_03.mp3」を置きます。
※http://pro-video.jp/voice/announce/より引用
file_name = "g_03.mp3"Whisperの実行
以下のコードを入力し、Shift+Enterを押して実行しましょう。
「verbose=True」を指定すると、処理最中の結果を表示させることができます。お好みで。
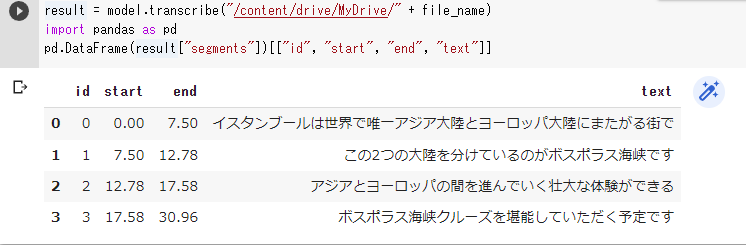
result = model.transcribe("/content/drive/MyDrive/" + file_name)
#result = model.transcribe("/content/drive/MyDrive/" + file_name, verbose=True)import pandas as pd
pd.DataFrame(result["segments"])[["id", "start", "end", "text"]]
#segments = result["segments"]
#for data in segments:
# print(data["text"])
以下のように出力されれば、成功です。ゆっくり丁寧なので、正確に認識できています。
応用してみましょう
動画からの文字起こし
Youtube動画の文字起こしをするように、コードを変えてみます。
modelの値もlargeに変えてみます。
yt-dlpで、Youtube動画の音声データをダウンロードして、input.mp3で保存しています。
残りは、同じ手法です。
ひろゆきさんの動画を、サンプルとして取り扱います。早口の場合の例になるかと。
https://youtu.be/u9eXBAnETVI
! pip install git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("large")! pip install yt-dlp
! rm input.mp3
! yt-dlp -x --audio-format mp3 https://youtu.be/u9eXBAnETVI -o "input.mp3"result = model.transcribe("input.mp3")
#result = model.transcribe("input.mp3", verbose=True)import pandas as pd
pd.DataFrame(result["segments"])[["id", "start", "end", "text"]]
#segments = result["segments"]
#for data in segments:
# print(data["text"])
以下の結果が出力されれば、成功です。
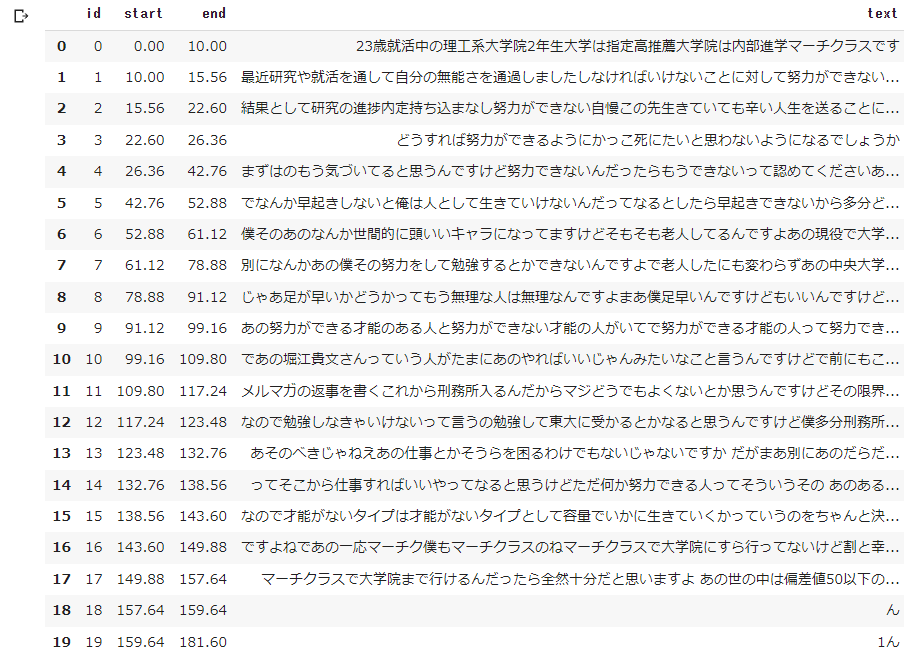
早口で話しているので、誤認識が多くなっていますね。
modelの値は、largeにすると、文の区切りが上手になりました。
人名は厳しそうです。しかし、ほとんど合っていると言って良い出来です。
字幕ファイルを作る
ジコログさんのブログを参考にしました。
最終的に、test.srtと言う字幕ファイルが作成するコードです。
また、早口なので1つの出力文章が長くなってしまう対策として、
whisperを改良して1つの出力文章の長さを変更できるソースを見つけました。
https://github.com/nyanta012/whisper
ソース中の「segment_length_ratio」⇒変数「slr」で調整しています。
※こちらのソースだと「verbose=True」オプションはエラーが出たので、留意してください。
字幕ファイルが自動で作成できれば、動画のテロップ作成は大幅に短縮できます。
! pip install git+https://github.com/nyanta012/whisper.git
import whisper
model = whisper.load_model("large")! pip install yt-dlp
! rm input.mp3
! yt-dlp -x --audio-format mp3 https://youtu.be/u9eXBAnETVI -o "input.mp3"# 出力される1文の長さの調整(デフォルト=1.0)
slr = 0.3
# 出力された字幕ファイルのタイムラグ調整(秒)
time_lag = 0.0
result = model.transcribe("input.mp3", segment_length_ratio=float(slr))#import pandas as pd
#pd.DataFrame(result["segments"])[["id", "start", "end", "text"]]! pip install srt
from datetime import timedelta
from srt import Subtitle
import srt
segments = result["segments"]
subs = []
for data in segments:
index = data["id"] + 1
start = data["start"] + time_lag
end = data["end"] + time_lag
text = data["text"]
sub = Subtitle(index=1, start=timedelta(
seconds=timedelta(seconds=start).seconds,
microseconds=timedelta(seconds=start).microseconds),
end=timedelta(
seconds=timedelta(seconds=end).seconds,
microseconds=timedelta(seconds=end).microseconds),
content=text, proprietary='')
subs.append(sub)
with open("test.srt", mode="w", encoding="utf-8") as f:
f.write(srt.compose(subs))!cat test.srt以下の結果になっていれば成功です。

segment_length_ratioの値は、動画によって適宜変更するとよいと思います。
※参考までに、改良したソースの中身を見させて頂いたところ、以下の通りでした。
すごいですね。
whisper/decording.py 99 + # segment length
100 + segment_length_ratio : Optional[float] = 1.0
101 +403 - self, tokenizer: Tokenizer, sample_begin: int, max_initial_timestamp_index: Optional[int]
406 + self, tokenizer: Tokenizer, sample_begin: int, max_initial_timestamp_index: Optional[int],
407 + segment_length_ratio: Optional[float]412 + self.segment_length_ratio = segment_length_ratio440 - if timestamp_logprob > max_text_token_logprob:
445 + if timestamp_logprob*self.segment_length_ratio > max_text_token_logprob:463 + self.segment_length_ratio = options.segment_length_ratio
464 +496 - ApplyTimestampRules(tokenizer, self.sample_begin, max_initial_timestamp_index)
503 + ApplyTimestampRules(tokenizer, self.sample_begin, max_initial_timestamp_index, self.segment_length_ratio)今回はここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日