Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた
久しく更新できていませんでした。
2023年5月にRinna社が公開した日本語に特化した36億パラメータを持つ対話GPT言語モデルを実行して行きます。
GPUメモリサイズに応じて、model読み込みのオプション変更できるようです。
- 指定なし
- torch_dtype=torch.float16
- load_in_8bit=True
- load_in_4bit=True
今回は、「load_in_8bit=True」を指定して動かしていきます。
Rinnaの日本語特化GPT言語モデル 実行
Google Colaboratoryにアクセスします。
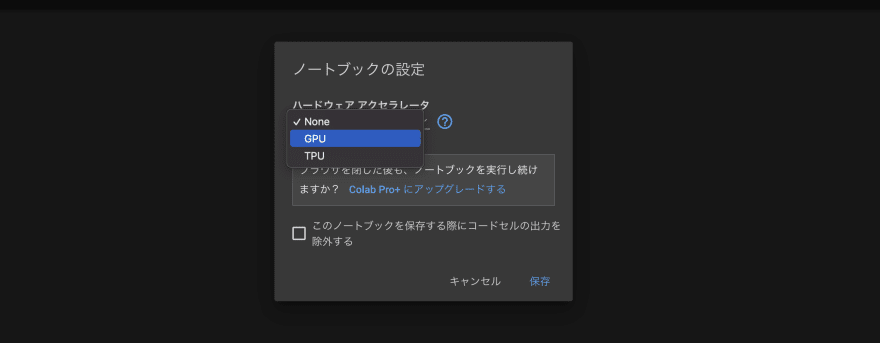
最初に、「編集」→「ノートブックの設定」から、
ハードウェアアクセラレートを「GPU」に設定しましょう。
以下のコマンドを入力し、Shift+Enterを押して実行しましょう。
GPUの情報が出てくれば、正常に設定変更できています。
!nvidia-smi続けてコードを記載してきます。必要なライブラリをインストールしましょう。
!pip install transformers
!pip install SentencePiece
!pip install Accelerate
!pip install bitsandbytes紹介されているサンプルコードのオプション部分を変更して、以下のコードで実行していきます。
「device_map={“”: 0}」の追加、「model.to(“cuda”)」部分をコメントアウトが追加で必要なようです。
(「model.to(“cuda”)」部分をコメントアウトしても、GPUで動作OK)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "rinna/japanese-gpt-neox-3.6b-instruction-ppo"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name,
# torch_dtype=torch.float16,
device_map={"": 0},
load_in_8bit=True
)
# if torch.cuda.is_available():
# model = model.to("cuda")prompt = [
{
"speaker": "ユーザー",
"text": "次の文章の訂正してください。「今日は熱い一日です」"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
repetition_penalty=1.1,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)モデルの読み込み時にライブラリの注意メッセージが出ましたが、無事に実行できました。
実行時のGPUメモリのサイズは5GB程度で、ちゃんとGoogle Colabの無料枠で動作しました。

npakaさんの記事にて、比較した結果が載っておりましたので、引用しますと、
設定なし(float32)だと15GB程度、float16だと8GB程度、int8だと5GB程度で動作するようです。
(通常、メモリ使用量が減る分、トレードオフとしてLLMの精度が低下するとのこと)
プロンプトの与え方を変えてみる
以下のようにサンプルを与えて、プロンプトを実行してみました。
実行部分のコードは変わりません。
prompt = [
{
"speaker": "ユーザー",
"text": "会社名:Apple Inc.、創立:1976年4月1日、従業員数:154,000人、事業内容:デジタル家庭電化製品、ソフトウェア、オンラインサービスの開発・販売"
},
{
"speaker": "システム",
"text": "Apple Inc.は、1976年4月1日に創立され、従業員数は154,000人を抱えます。事業内容としては、デジタル家庭電化製品、ソフトウェア、オンラインサービスの開発・販売を行っています。"
},
{
"speaker": "ユーザー",
"text": "会社名:Meta Platforms, Inc.、創立:2004年2月4日、従業員数:52,534人、事業内容:世界的に展開されているソーシャル・ネットワーキング・サービスの運営"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
repetition_penalty=1.1,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)結果は以下の通り。思惑通りの文章を作成してくれました。
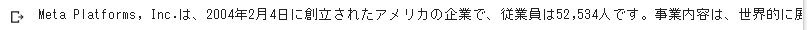
Meta Platforms, Inc.は、2004年2月4日に創立されたアメリカの企業で、従業員は52,534人です。事業内容は、世界的に展開されているソーシャル・ネットワーキング・サービスの運営です。</s>
サンプルの与え方次第で可能性が広がりそうです。
既存のサンプルを元にして文章を作成する分には、精度高くできそうな期待感があります
今回はとりあえずサンプルコードを元に、Google Colabの無料枠で実行したのですが、
使い方次第(プロンプトの与え方次第)ですごい使い勝手が良くなりそうです。
外部にデータを送らずにローカルで実行できる分、外部に情報を提供できない環境で有用かと。
とりあえず、ここまで。
参考
CTranslate2を使用してモデル変換を実行すると、軽量+CPUのみでも推論の実行が可能になるとのこと。Google Colabの無料枠では変換に必要なメモリが足りず試していないので、参考に書き留めておきます。(GPUがなくても、メモリさえ大容量が確保できれば実行できるので、期待感があります)
→ メモリ64GBの環境でテストする機会があり、実際に動かしてみました。(2023/10/29)。
参考情報は、同じくnpakaさんの記事より。
<モデルの変換>
!pip install ctranslate2
!pip install sentencepiece transformers!ct2-transformers-converter \
--model rinna/japanese-gpt-neox-3.6b-instruction-ppo \
--quantization int8 \
--output_dir ./rinna_ppo-ct2 \
--low_cpu_mem_usage※「You are using the default legacy behaviour of the <class …」とメッセージが出ますが、
とりあえず「–output_dir」で指定したフォルダに、3個のファイルが問題なく作成されているはずです。
(config.json、model.bin、vocabulary.txt)
下記のtokenizerオプションに「legacy=False」を入れることで、モデル実行時には上記表示は回避できます。
<推論の実行>
import ctranslate2
import transformers
import torch
model_name = "rinna/japanese-gpt-neox-3.6b-instruction-ppo"
ct2_model = "./rinna_ppo-ct2"
# ジェネレーターとトークナイザーの準備
device = "cuda" if torch.cuda.is_available() else "cpu"
generator = ctranslate2.Generator(ct2_model, device=device)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, use_fast=False, legacy=False)prompt = [
{
"speaker": "ユーザー",
"text": "次の文章の訂正してください。「今日は熱い一日です」"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)tokens = tokenizer.convert_ids_to_tokens(
tokenizer.encode(prompt, add_special_tokens=False)
)
results = generator.generate_batch(
[tokens],
max_length=64,
sampling_topk=10,
sampling_temperature=0.7,
include_prompt_in_result=False,
)
text = tokenizer.decode(results[0].sequences_ids[0])
print(text)
- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日