pyopenjtalk , Tacotron2 , gTTS 音声合成AIを簡単に使ってみた
今回は、Whisper(音声・動画の自動書き起こしAI)とは逆に、文章から音声を作成する
合成音声AIを使ってみました。
2つのライブラリを使用して、比較もしてみました。
- pyopenjtalk : OpenJTalkをベースとしたテキスト処理フロントエンド
まさにAIが話していると分かる音声合成AI - Tacotron2 : かなり自然。ただ、音声合成の処理時間がかなり長い。
自分の声などを追加で学習することできるらしい。 - gTTS : Googleが提供するText-to-Speech
Google Translateの音声合成APIと連携するためのPythonライブラリ
ソースコードはそこまで複雑ではありませんので、サクッと説明していきたいと思います。
pyopenjtalk
pyopenjtalkで公開されている音声合成AIです。
早速、Google Colaboratory上で動かしていきたいと思います。
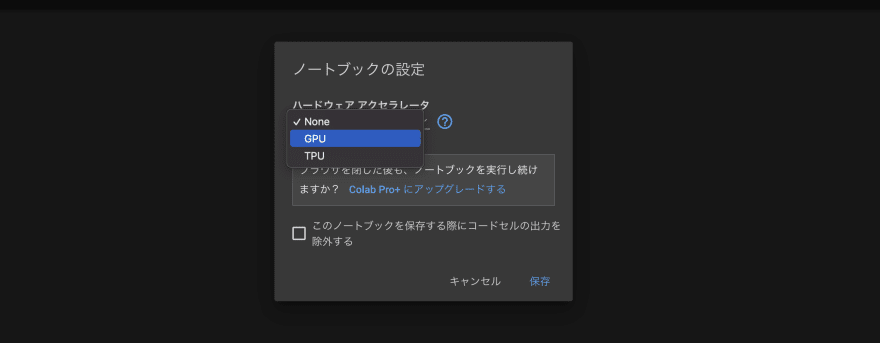
最初に、「編集」→「ノートブックの設定」から、
ハードウェアアクセラレートを「GPU」に設定しましょう。
以下のコマンドを入力し、Shift+Enterを押して実行しましょう。
GPUの情報が出てくれば、正常に設定変更できています。
!nvidia-smi続けて、ソースを記述して実行していきます。
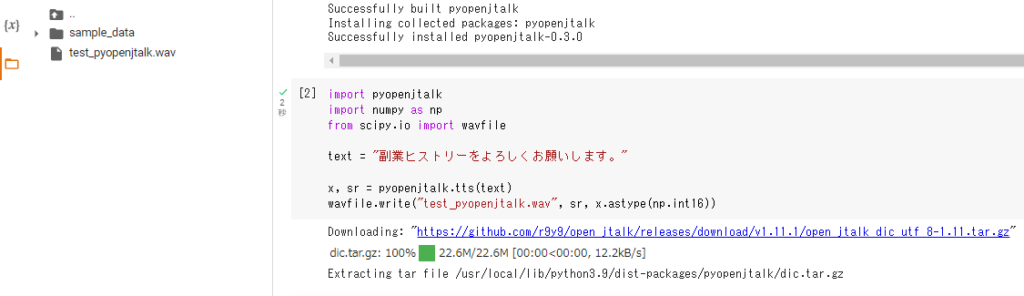
!pip install pyopenjtalkimport pyopenjtalk
import numpy as np
from scipy.io import wavfile
text = "副業ヒストリーをよろしくお願いします。"x, sr = pyopenjtalk.tts(text)
wavfile.write("test_pyopenjtalk.wav", sr, x.astype(np.int16))
!rm "test_pyopenjtalk.mp3"
!ffmpeg -i "test_pyopenjtalk.wav" "test_pyopenjtalk.mp3"
!rm "test_pyopenjtalk.wav"一瞬で完了します。早いです。
左側のファイル一覧に音声ファイルが作成されているので、ダウンロードしましょう。
以下のようなファイルが作成されるはずです。いかにも機械音声です。
Tacotron2
Tacotron2で公開されている音声合成AIです。
こちらも、Google Colaboratory上で動かしていきたいと思います。
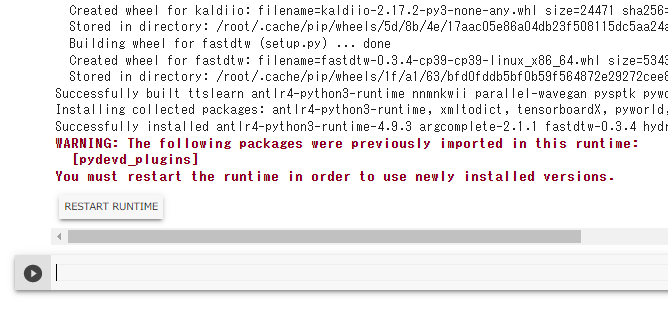
!pip install ttslearn元々インストールされていたランタイムより新しいバージョンがインストールされたため、
ランタイムのリスタートを求められます。ボタンを押しましょう。
from ttslearn.tacotron import Tacotron2TTS
import numpy as np
from scipy.io import wavfile
text = "副業ヒストリーをよろしくお願いします。"engine = Tacotron2TTS()
x, sr = engine.tts(text)
wavfile.write("test_tacotron2.wav", sr, x.astype(np.int16))
!rm "test_tacotron2.mp3"
!ffmpeg -i "test_tacotron2.wav" "test_tacotron2.mp3"
!rm "test_tacotron2.wav"先ほどと打って変わって、処理に5分くらいかかります。
左側のファイル一覧に音声ファイルが作成されているので、ダウンロードしましょう。
以下のようなファイルが作成されるはずです。
先ほど作成された音声と比べて、かなり自然な仕上がりです。
gTTS
後日、追加しました。
gTTSで公開されているライブラリです。これまでの2つと異なり、直接MP3で出力可能です。
また、API処理なので、ローカル環境でも簡単に処理ができます。
!pip install gttsfrom gtts import gTTS
text = "副業ヒストリーをよろしくお願いします。"
tts = gTTS(text=text, lang='ja')
tts.save('gtts.mp3')以下のようなファイルが作成されるはずです。
pyopenjtalkよりは自然に聞こえますが、Tacotron2よりは機械的に聞こえます。
コードも短く済んで処理も早いので、一番バランスが良いかもしれません。
テキストファイルから音声合成する
一文ずつ入力するのは手間ですので、テキストファイルの内容をまとめて処理します。
処理が軽いので、pyopenjtalkを使用したコードを記載します。
今回は、音声合成したい文章は下記の通りで、test.txtに書かれているとします。
文字コードはUTF-8です。メモ帳で開いたときには、右下に文字コードが出るので確認しましょう。
左側のファイル一覧にドラック&ドロップして、アップロードしておきましょう。
ChatGPTは、OpenAIによって開発された大規模な言語モデルの1つです。
ChatGPTは、自然言語処理における会話や文章生成などのタスクを行うことができます。
ChatGPTは、大量のテキストデータを学習し、人間のような応答を生成することができます。
ChatGPTは、質問に答える、文書生成、文章の要約、文章の翻訳など、様々な自然言語処理タスクに応用されます。さて、コードを記述してきましょう。
!pip install pyopenjtalkimport pyopenjtalk
import numpy as np
from scipy.io import wavfilei = 0
with open('test.txt', 'r', encoding="utf-8") as f:
for line in f:
line = line.rstrip() # 読み込んだ行の末尾には改行文字があるので削除
x, sr = pyopenjtalk.tts(line)
wav_file_name = "test_pyopenjtalk_" + format(i, '02') + ".wav"
mp3_file_name = "test_pyopenjtalk_" + format(i, '02') + ".mp3"
wavfile.write(wav_file_name, sr, x.astype(np.int16))
!rm $mp3_file_name
!ffmpeg -i $wav_file_name $mp3_file_name
!rm $wav_file_name
i = i + 1test_pyopenjtalk_00.mp3~test_pyopenjtalk_XX.mp3まで作成されます。
行数が多くて100を超える場合、format(i, ’02’)→format(i, ’03’)と適宜変更してください。
一応、Tacotron2のバージョンのコードも記載しておきます。
!pip install ttslearnfrom ttslearn.tacotron import Tacotron2TTS
import numpy as np
from scipy.io import wavfileengine = Tacotron2TTS()
i = 0
with open('test.txt', 'r', encoding="utf-8") as f:
for line in f:
line = line.rstrip() # 読み込んだ行の末尾には改行文字があるので削除
x, sr = engine.tts(line)
wav_file_name = "test_tacotron2_" + format(i, '02') + ".wav"
mp3_file_name = "test_tacotron2_" + format(i, '02') + ".mp3"
wavfile.write(wav_file_name, sr, x.astype(np.int16))
!rm $mp3_file_name
!ffmpeg -i $wav_file_name $mp3_file_name
!rm $wav_file_name
i = i + 1後日、追加分。gTTSのバージョンのコードも載せておきます。
!pip install gttsfrom gtts import gTTS
i = 0
with open('test.txt', 'r', encoding="utf-8") as f:
for line in f:
line = line.rstrip() # 読み込んだ行の末尾には改行文字があるので削除
tts = gTTS(text=line, lang='ja')
mp3_file_name = "test_gtts_" + format(i, '02') + ".mp3"
tts.save(mp3_file_name)
i = i + 1とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日