Python Webスクレイピング 実践してみた③
前回の記事(Webスクレイピング 実践②)の続きを記載してきます。
前回までに、実際にウェブサイトから情報を取得してCSVファイルに出力するまで学習しました。
今回は、以下のようなパターンを想定して、Seleniumを使った方法を記載したいと思います。
- Google、Yahooなどで、指定したキーワードの検索結果をスクレイピングをしたい。
- ログインが必要なサイトで、ログイン後に表示される情報をスクレイピングしたい。
(その他、ブラウザに何かしらの入力・操作が必要となる場合のスクレイピング)
特にブラウザの操作を必要としない場合は、これまでの記事の方法でスクレイピングできます。
※逆に、Seleniumを使用しない方が処理速度が速くなります。
Selenuimを用いてブラウザを起動する
Seleniumは、ブラウザをPythonのコードを用いて操作することを可能にするライブラリです。
Seleniumが操作するブラウザ(Chrome,Firefox,Edgeなど)に合わせて、WebDriverを用意する必要があります。
しかし、WebDriver_Managerをインストールすることで、環境に合わせたWebDriverを自動でインストールしてくれます。
便利ですので、Seleniumと合わせてインストールしておきましょう。
これまでに使用してきたライブラリと共に記載しておきます。
!pip install requests
!pip install selenium
!pip install webdriver_manager今回は、Chromeブラウザを操作することとします。下記のコードでChromeブラウザを起動させることができます。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 起動したことを確認するため、10秒待ちます
time.sleep(10)
# ブラウザを閉じる
browser.quit()
※後日追記
seleniumのバージョン4.6 からは、ドライバのインストールツールが導入されたため、
「webdriver_manager」が不要で、かつimportやブラウザの起動手順も異なるようです。
!pip install requests
!pip install seleniumfrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
# ブラウザの起動
options = Options()
browser = webdriver.Chrome(options=options)
# 起動したことを確認するため、10秒待ちます
time.sleep(10)
# ブラウザを閉じる
browser.quit()指定したURLにアクセスする
「browser.quit()」を記載していませんので、プログラムを再実行するたびにChromeブラウザが起動します。
「×」ボタンで閉じてしまって問題はありません。
※意図的に複数のブラウザを操作したい場合、起動時のインスタンス名を分けましょう。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "https://www.yahoo.co.jp/"
browser.get(url)
要素の取得
要素を見つけ出すために、ソースコードの情報を見る必要があります。
Chromeの場合は「F12」を押すと、開発者ツールが起動します。
続けて、左上の矢印の書いてあるボタンを押して、ページ上を指定すると、その部分のコードを参照できます。
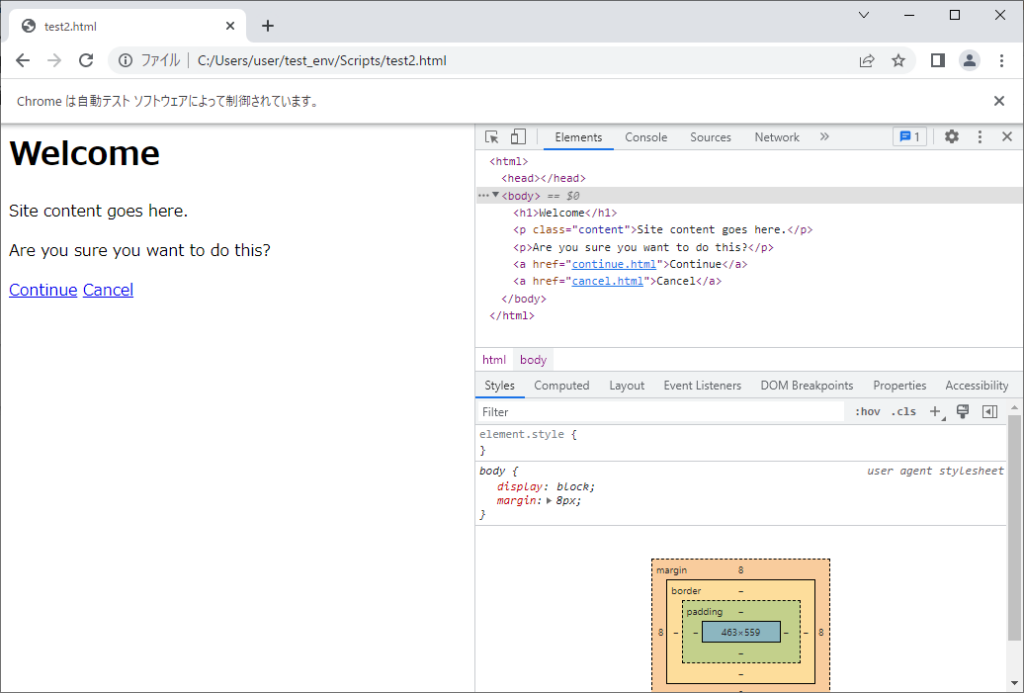
指定したURLへアクセス出来たら、ページ内の要素を取得する必要があります。
Seleniumでページ内の要素を取得するためのメソッドには、以下があります。
※seleniumのバージョン4.3.0から、find_element_by_*系のメソッドが廃止されて使えなくなっています。
- find_element(By.ID,’検索したい要素’) (旧:find_element_by_id)
- find_element(By.NAME,’検索したい要素’) (旧:find_element_by_name)
- find_element(By.XPATH,’検索したい要素’) (旧:find_element_by_xpath)
- find_element(By.LINK_TEXT,’検索したい要素’) (旧:find_element_by_link_text)
- find_element(By.PARTIAL_LINK_TEXT,’検索したい要素’) (旧:find_element_by_partial_link_text)
- find_element(By.TAG_NAME,’検索したい要素’) (旧:find_element_by_tag_name)
- find_element(By.CLASS_NAME,’検索したい要素’) (旧:find_element_by_class_name)
- find_element(By.CSS_SELECTOR,’検索したい要素’) (旧:find_element_by_css_selector)
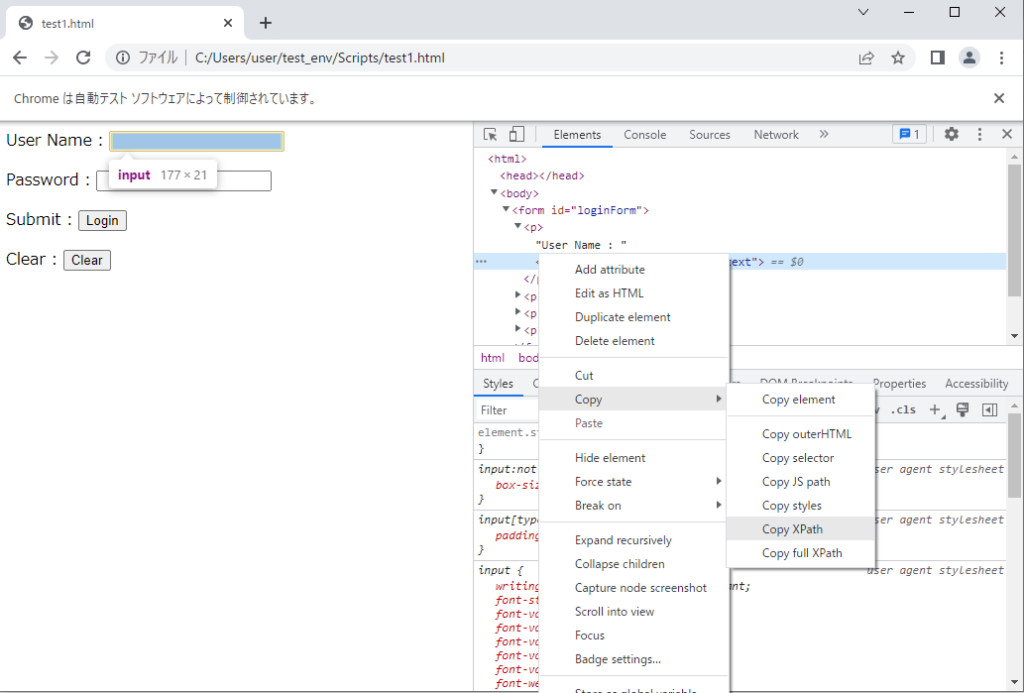
例えば、下記のようなHTMLページの場合を考えます。「test1.html」として保存しておきましょう。
<html>
<body>
<form id="loginForm">
<p>User Name : <input name="username" type="text" /></p>
<p>Password : <input name="password" type="password" /></p>
<p>Submit : <input name="continue" type="submit" value="Login" /></p>
<p>Clear : <input name="continue" type="button" value="Clear" /></p>
</form>
</body>
</html>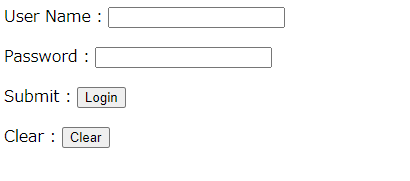
先ほど保存した「test1.html」のパスは、必要に応じて書き換えてください。
ID,NAMEで検索する場合のコードです。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "file:///C:/Users/user/test_env/Scripts/test1.html"
browser.get(url)
# フォーム要素の取得
login_form = browser.find_element(By.ID,'loginForm')
# ユーザー名・パスワード要素の取得
username = browser.find_element(By.NAME,'username')
password = browser.find_element(By.NAME,'password')
# 取得対象は最初の要素になるので、"Login"のcontinue要素を取得しています
conti = browser.find_element(By.NAME,'continue')
print(login_form)
print(username)
print(password)
print(conti)
XPATHで検索する場合のコードです。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "file:///C:/Users/user/test_env/Scripts/test1.html"
browser.get(url)
# フォーム要素の取得(同じ結果)
#login_form = browser.find_element(By.XPATH,'//form[@id="loginForm"]')
login_form = browser.find_element(By.XPATH,'//form[1]')
# ユーザー名要素の取得(同じ結果)
#username = browser.find_element(By.XPATH,'//input[@name="username"]')
username = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[1]/input')
# パスワード名要素の取得(同じ結果)
#password = browser.find_element(By.XPATH,'//input[@name="password"]')
password = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[2]/input')
# 送信ボタンの要素を取得(同じ結果)
#submit_button = browser.find_element(By.XPATH,'//input[@name="continue"][@type="submit"]')
submit_button = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[3]/input')
# クリアボタンの要素を取得(同じ結果)
#clear_button = browser.find_element(By.XPATH,'//input[@name="continue"][@type="button"]')
clear_button = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[4]/input')
print(login_form)
print(username)
print(password)
print(submit_button)
print(clear_button)
XPATHで検索する場合、Chromeの開発者ツールのコード上から、取得することが可能です。楽です。
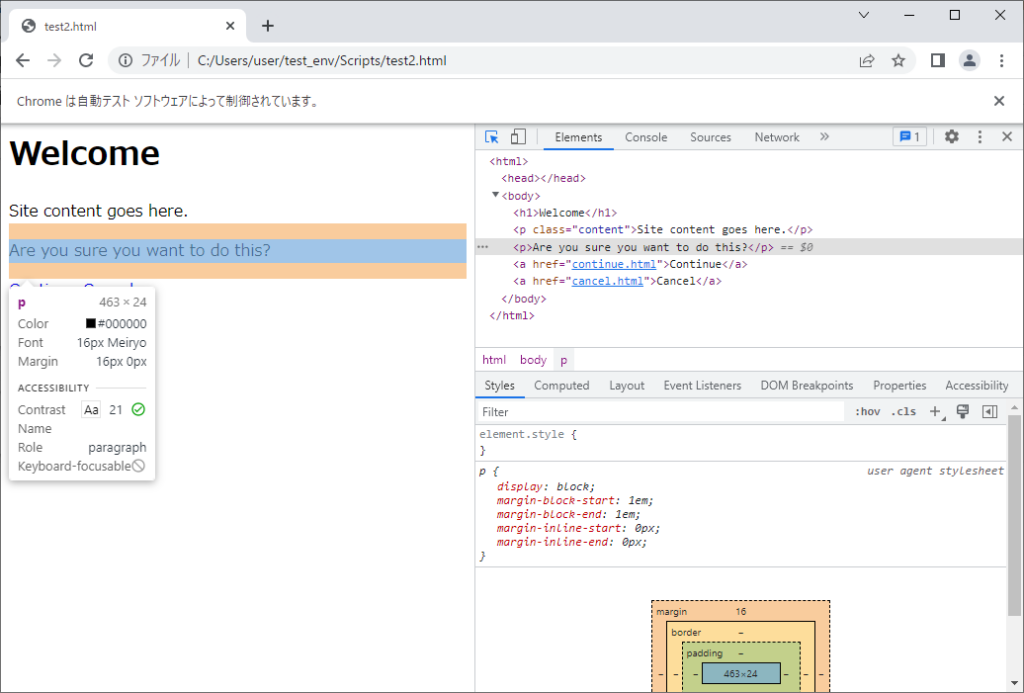
例えば、下記のようなHTMLページの場合を考えます。今度は「test2.html」として保存しておきましょう。
<html>
<body>
<h1>Welcome</h1>
<p class="content">Site content goes here.</p>
<p>Are you sure you want to do this?</p>
<a href="test1.html">Continue</a>
<a href="test2.html">Cancel</a>
</body>
<html>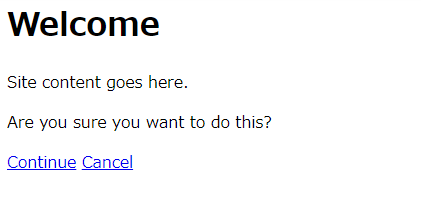
先ほど保存した「test2.html」のパスは、必要に応じて書き換えてください。
残りの方法で検索する場合のコードです。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "file:///C:/Users/user/test_env/Scripts/test2.html"
browser.get(url)
# リンク要素の取得
continue_link = browser.find_element(By.LINK_TEXT,'Continue')
continue_partial_link = browser.find_element(By.PARTIAL_LINK_TEXT,'Conti')
# タグ要素の取得
heading1 = browser.find_element(By.TAG_NAME,'h1')
# CSSセレクタの要素の取得
content = browser.find_element(By.CSS_SELECTOR,'p.content')
print(continue_link)
print(continue_partial_link)
print(heading1)
print(content)
取得した要素への操作
例えば、下記のようなHTMLページの場合を考えます。今度は「test3.html」として保存しておきましょう。
Javascriptは、Submitボタンが押されたら、
<html>
<body>
<form id="loginForm">
<p>User Name : <input name="username" type="text" /></p>
<p>Password : <input name="password" type="password" /></p>
<p>Submit : <input name="continue" type="submit" value="Login" /></p>
<p>Clear : <input name="continue" type="button" value="Clear" /></p>
</form>
<div id="display"></div>
<script>
const form = document.getElementById("loginForm");
const display = document.getElementById("display");
form.addEventListener("submit", (event) => {
event.preventDefault();
const formData = new FormData(event.target);
const username = formData.get("username");
const password = formData.get("password");
display.innerHTML = `
<p>User Name : ${username}</p>
<p>Password : ${password}</p>
`;
});
</script>
</body>
</html>先ほど保存した「test3.html」のパスは、必要に応じて書き換えてください。
ID・パスワードを入力して、送信ボタンを押すような場合、以下のようになります。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "file:///C:/Users/user/test_env/Scripts/test3.html"
browser.get(url)
# ユーザー名・パスワードの入力情報
username_text = "kaji0620"
password_text = "12345678"
# ユーザー名要素の取得
username = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[1]/input')
# ユーザー名要素に入力
username.send_keys(username_text)
# パスワード名要素の取得
password = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[2]/input')
# パスワード要素に入力
password.send_keys(password_text)
# 送信ボタンの要素を取得
submit_button = browser.find_element(By.XPATH,'//*[@id="loginForm"]/p[3]/input')
# 送信ボタンをクリック
submit_button.click()以下のように「Clear」ボタンの下に入力した情報が出力されれば、OKです。
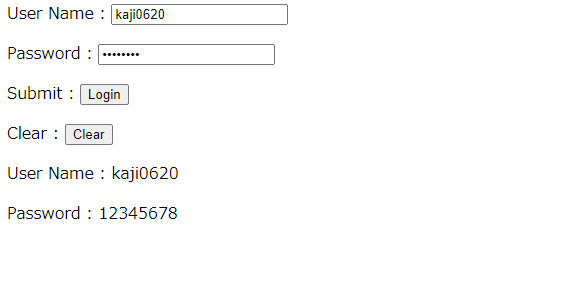
先ほどの「test2.html」を利用して、
テキストの取得、リンクの取得、リンクを押すような場合、以下のようになります。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "file:///C:/Users/user/test_env/Scripts/test2.html"
browser.get(url)
# リンク要素の取得
continue_partial_link = browser.find_element(By.PARTIAL_LINK_TEXT,'Conti')
print("Link Text : " + continue_partial_link.text)
print("Link URL : " + continue_partial_link.get_attribute('href'))
continue_partial_link.click()
「Continue」のリンクがクリックされて、「test1.html」へ移動すれば、OKです。
例)Yahooの検索結果の上位10項目のタイトルの取得
具体的に、Yahooのページにアクセスし、指定キーワードを検索してみるコードを記載します。
今回の検索キーワードは「副業 おじさん 記録」です。
画面遷移等で時間を要する部分がありますので、その間、待機させる必要があります。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
import numpy as np
import csv
# ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())
# 指定URLへのアクセス
url = "https://www.yahoo.co.jp/"
browser.get(url)
search_text = "副業 おじさん 記録"
# 検索テキストボックス要素の取得
search_textbox = browser.find_element(By.XPATH,'//*[@id="ContentWrapper"]/header/section[1]/div/form/fieldset/span/input')
# 検索送信ボタン要素の取得
search_submit = browser.find_element(By.XPATH,'//*[@id="ContentWrapper"]/header/section[1]/div/form/fieldset/span/button')
# 検索キーワードの入力
search_textbox.send_keys(search_text)
# 検索送信ボタンのクリック
search_submit.click()
# 検索結果が表示されるまで待機
time.sleep(3)
# 結果を代入するリストの初期化
num = 10 + 1
result = np.zeros((num,2), dtype='object')
# タイトル行の追加
result[0][0] = 'title'
result[0][1] = 'url'
# 検索結果10件分のタイトル・URLを取得する
for i in range(1,num):
result_tmp_h3 = browser.find_element(By.XPATH,'//*[@id="contents__wrap"]/div[1]/div[2]/div[' + str(i) + ']/div/section/div[1]/div/div/a/h3')
result_tmp_a = browser.find_element(By.XPATH,'//*[@id="contents__wrap"]/div[1]/div[2]/div[' + str(i) + ']/div/section/div[1]/div/div/a')
result[i][0] = result_tmp_h3.text
result[i][1] = result_tmp_a.get_attribute('href')
# CSVファイルに書き出し
with open("result_list.csv", "w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(result)
# ブラウザを閉じる
browser.quit()以下のようなCSVファイルが作成されていればOKです。
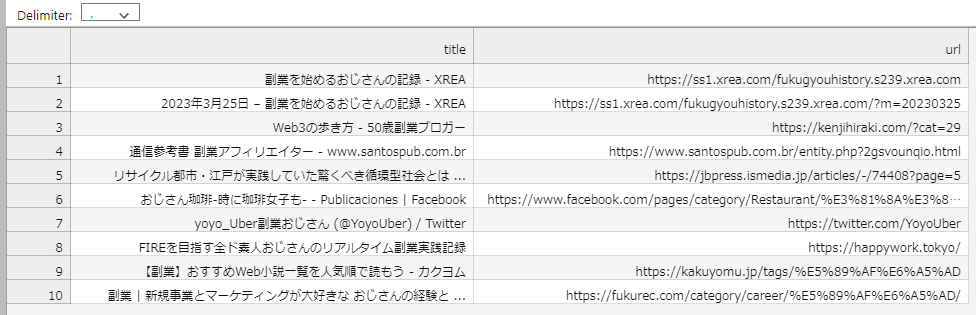
Seleniumを用いて、ブラウザを操作して情報を取得する方法が分かりました。
もっと上手に動かす方法もあるかと思いますが、とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日