Python WordCloudを学習してみた
WordCloudとは、文中の出現頻度の高い単語を抽出して可視化するツールです。
日々の情報収集の結果を、視覚的に捉えるのには有効なツールと言えます。
某情報番組では、毎日、番組の冒頭で紹介されていたので、見たことがある人も多いのでは。
公式サイトのサンプル画像を載せておきます。

WordCloudを実行してみる(英語)
最初に、WordCloudのインストールをしておきましょう。
良く発生するエラーについて記載しましたので、参考にしてください。
!pip install wordcloud※pipインストールの際に以下のようなエラーが出た場合、エラーメッセージのURLから「Build Tools」→「C++によるデスクトップ開発」をインストールして、再実行しましょう。
…(省略)…
building ‘wordcloud.query_integral_image’ extension
error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: https://visualstudio.microsoft.com/visual-cpp-build-tools/…(省略)…
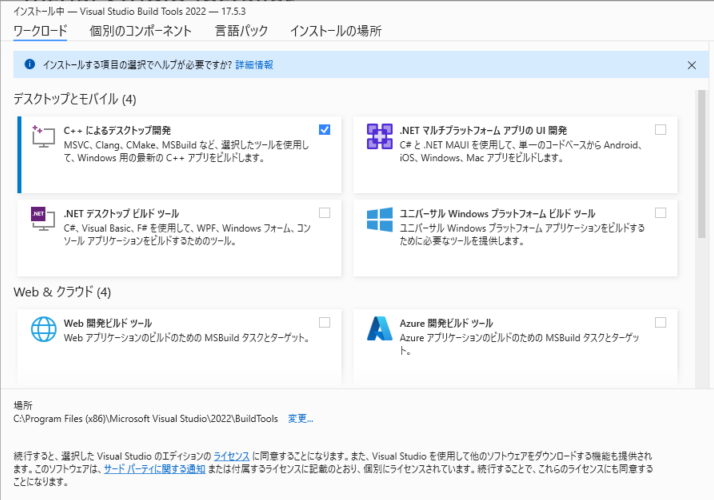
※pipインストールの際に以下のようなエラーが出た場合、「pip install wordcloud」でのインストールがPython3.11に対応していない(最新のソースに反映されていない)ため発生しています。
…(省略)…
wordcloud/query_integral_image.c(196): fatal error C1083: Cannot open include file: ‘longintrepr.h’: No such file or directory
…(省略)…
GitHub経由でインストールすると、問題なく進めることができます。
参考元:https://github.com/amueller/word_cloud/issues/702#issuecomment-1445145114
!pip install git+https://github.com/amueller/word_cloud.git無事にWordCloudのインストールが終わりましたら、以下のコードを実行してみましょう。
公式サイトで提供されている英語テキスト(米国憲法の文章)を用いて作成しています。
import requests
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 公式サイトのサンプルテキストのURL
url = "https://raw.githubusercontent.com/amueller/word_cloud/master/examples/constitution.txt"
# ファイルの取得
response = requests.get(url)
# ファイルのテキストの取得
text = response.text
# 画像作成
wordcloud = WordCloud(width=800, height=600, background_color='white').generate(text)
# Wordcloudを表示
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 画像保存
#wordcloud.to_file("result_wordcrowd.png")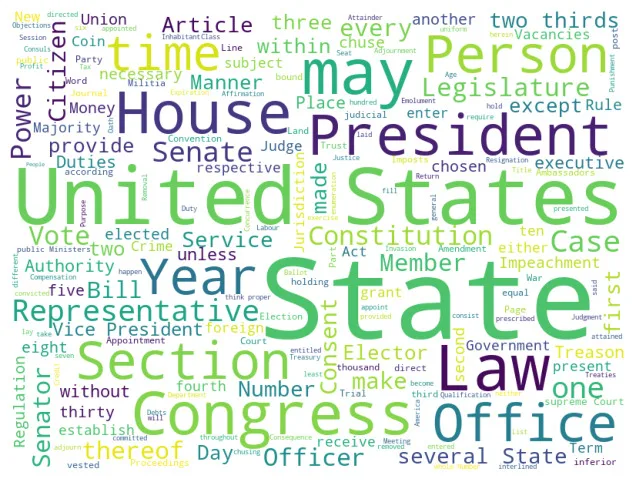
マスクイメージを用いて、任意の形に出力することも可能です。
以下のマスク画像(アメリカ国土)を「America.png」で用意して、先ほどと同じコードを実行してみます。
また、StopWordsのオプションを使用すると、結果から除外するキーワードを手動で指定することができます。
※英語の場合、指定しなくてもBuild-inされている除外ワードが自動で適用されます。
https://github.com/amueller/word_cloud/raw/master/wordcloud/stopwords
日本語の場合に、このオプションを使用する場面が出てくるかと思います。

import requests
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# 公式サイトのサンプルテキストのURL
url = "https://raw.githubusercontent.com/amueller/word_cloud/master/examples/constitution.txt"
# ファイルの取得
response = requests.get(url)
# ファイルのテキストの取得
text = response.text
# 除外キーワード
stop_words_en = ['am', 'are', 'is', 'was', 'were', 'be', 'and', 'or', 'but', 'as', 'in', 'to', 'for', 'of', 'by', 'on', 'a', 'an', 'will', 'shall', 'this', 'that', 'it', 'the', 'what', 'when', 'where', 'which']
# マスク画像の読み込み
mask = np.array(Image.open("America.png"))
# 画像作成(枠線なし)
#wordcloud = WordCloud(width=800, height=600, background_color='white', mask=mask, stopwords=stop_words_en).generate(text)
# 画像作成(枠線あり)
wordcloud = WordCloud(width=800, height=600, background_color='white', mask=mask, stopwords=stop_words_en, contour_width=3, contour_color='steelblue').generate(text)
# Wordcloudを表示
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 画像保存
#wordcloud.to_file("result_wordcrowd.png")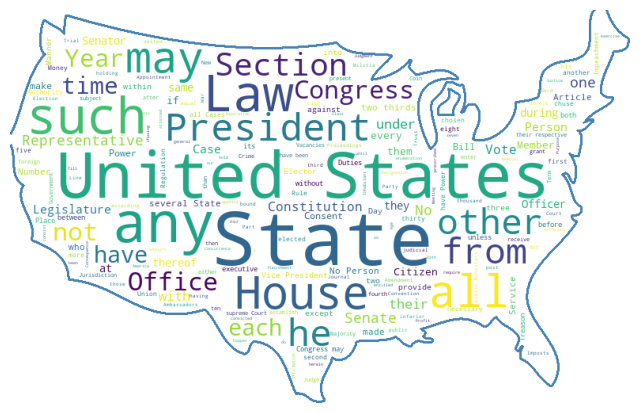
WordCloudを実行してみる(日本語)
英語の場合、単語と単語の間にスペースがありますので、文字列から単語の頻出度合いを簡単に把握できます。
一方で、日本語の場合は、単語・文字列がつながっているので、WordCloudでは把握・判定できません。
そこで、日本語の場合は文字列を分けるために「形態素解析」と言うことをする必要があります。
※形態素:意味を持つ言語の最小単位
※形態素解析:文字列を品詞(名詞・動詞・助詞など)に分割して、必要なキーワードを抜き出すことです。
形態素解析には、2つの代表的な方法があります。一応、両方のパターンでコードを記載していきます。
- Mecab : がっつりと形態素解析をやりたいという場合
- Janome : 気軽に形態素解析をやりたいという場合
青空文庫の「銀河鉄道の夜」(宮沢賢治)の作品を取得して、コードを書いていきます。
まず、作品の文章を取得しましょう。
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# 作品のURL
url = "https://www.aozora.gr.jp/cards/000081/files/43737_19215.html"
# 作品のHTMLファイルの取得
res = requests.get(url)
# エンコーディングが異なる場合のエンコード処理(BeautifulSoupを使わない場合)
#res.encoding = res.apparent_encoding
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 文章を取得する
text = soup.text
# 最初の500文字を表示(プレビュー用)
print(text[:500])
Mecabを使用する場合
まずは、Mecabをインストールします。下記のURLからWindowsインストーラーをダウンロードします。
https://github.com/ikegami-yukino/mecab/releases/
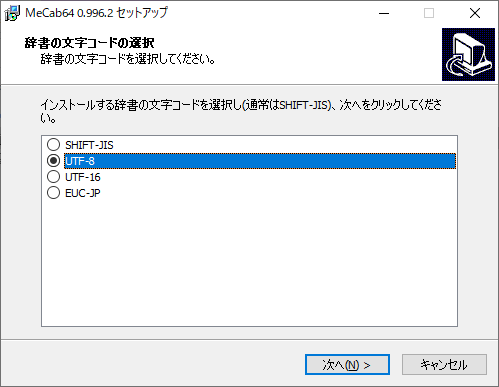
文字コードはUTF-8にしておきましょう。
スタートメニューに登録は必要ないので、チェックを入れました。
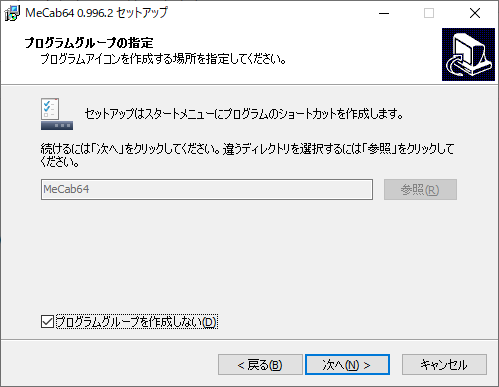
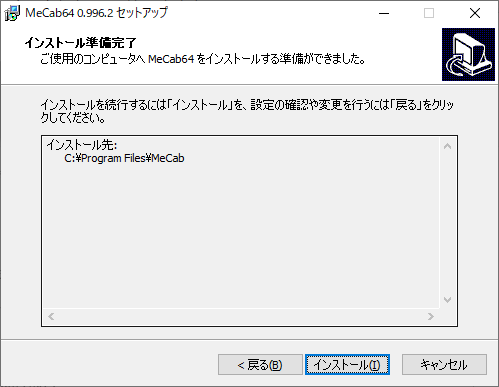
続けて、パスを追加します。システムのプロパティを開き、環境変数を選択します。
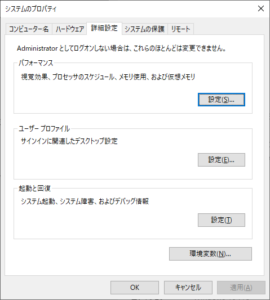
下側の「システム環境変数」の「path」を選択して、「編集」ボタンを押します。
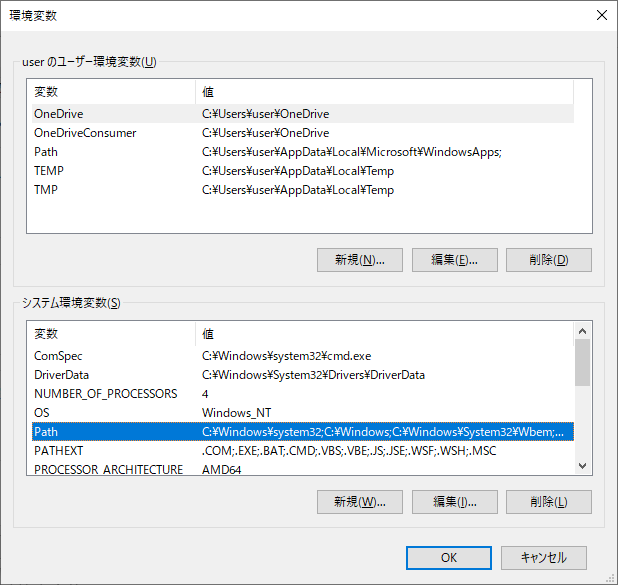
ご自身の環境に合わせて書き換える必要がありますが、
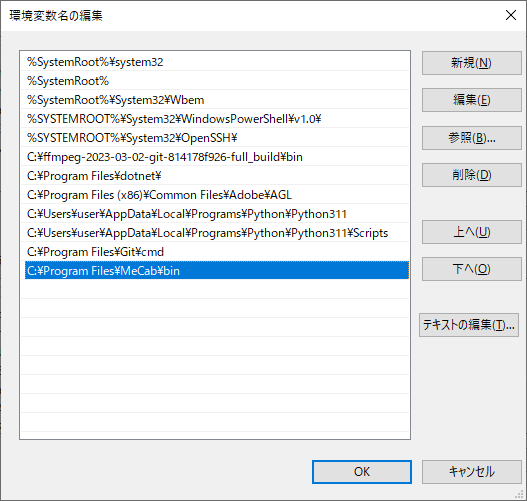
「新規」ボタンを押下して以下を追加します。
「C:\Program Files\MeCab\bin」
スタートメニューを右クリックして、「ファイル名を指定して実行」を選択し、
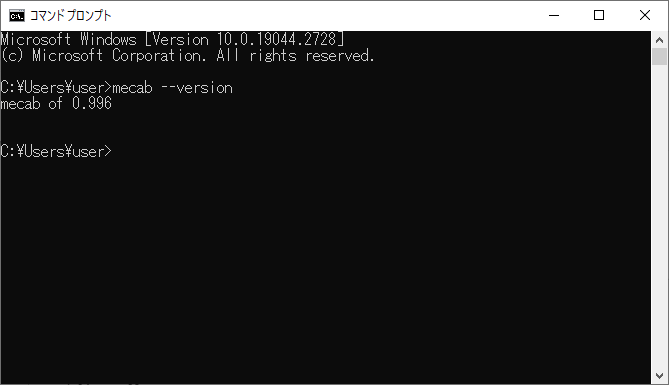
「cmd」と記入して「OK」を押します。コマンドプロンプトが起動します。
起動後、「mecab –version」と入力して、正しくバージョン情報が出てくれば、OKです。
Windowsインストーラー実施後、pipインストールを実施します。
!pip install mecabMecabの実行している内容が確認したい場合、以下のコードを実行すると分かります。
文章を品詞ごとに分解しているのが分かると思います。
import MeCab
# Mecabの起動
tagger = MeCab.Tagger()
tagger.parse('')
text = "Mecabを実行すると、このような結果になります。"
# 解析結果を変数に入れる
tokens = tagger.parse(text)
# 解析結果を表示する
print(tokens)
早速、取得した文章を形態素解析します。
import MeCab
import re
# Mecabの起動
tagger = MeCab.Tagger()
parsed = tagger.parse(text)
# 1行ごとにリストに分ける
lines = parsed.split('\n')
word_list = []
for line in lines:
# スペース、カンマでデータを区切る
tmp = re.split('\t|,',line)
# tmpの長さが1未満の場合はスキップする
if len(tmp) < 2:
continue
# 名詞のみ、ワードを取り出す
if tmp[1] == '名詞':
word_list.append(tmp[0])
# word_listを文字列に変換する
word_chain = ' '.join(word_list)
# 最初の20単語だけ表示(プレビュー用)
print(word_list[0:20])
print(word_chain[0:20])
形態素解析した結果を、WordCloudに投げ込んでみます。
ただし、日本語が文字化けしてしまうので、日本語フォントの指定をする必要があります。
また、日本語の場合は漢字一文字の単語もあるので、一文字以上の結果を出るようにオプション(regexp=”[\w’]+”)を追加します。
import requests
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# フォントの指定
font_path = "meiryo.ttc"
# 除外キーワード
stop_words_ja = ['もの', 'こと', 'とき', 'そう', 'たち', 'これ', 'よう', 'これら', 'それ', 'すべて','の','ん']
# 画像作成
wordcloud = WordCloud(width=800, height=600, font_path=font_path, background_color='white', stopwords=stop_words_ja, regexp="[\w']+").generate(word_chain)
# Wordcloudを表示
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 画像保存
#wordcloud.to_file("result_wordcrowd.png")
分割して記載して分かりにくい部分もあると思いますので、まとめたコードを記載しておきます。
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import MeCab
import re
#----作品の文章の取得----
# 作品のURL
url = "https://www.aozora.gr.jp/cards/000081/files/43737_19215.html"
# 作品のHTMLファイルの取得
res = requests.get(url)
# エンコーディングが異なる場合のエンコード処理(BeautifulSoupを使わない場合)
#res.encoding = res.apparent_encoding
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 文章を取得する
text = soup.text
#----Macabによる形態素解析----
# Mecabの起動
tagger = MeCab.Tagger()
parsed = tagger.parse(text)
# 1行ごとにリストに分ける
lines = parsed.split('\n')
word_list = []
for line in lines:
# スペース、カンマでデータを区切る
tmp = re.split('\t|,',line)
# tmpの長さが1未満の場合はスキップする
if len(tmp) < 2:
continue
# 名詞のみ、ワードを取り出す
if tmp[1] == '名詞':
word_list.append(tmp[0])
# word_listを文字列に変換する
word_chain = ' '.join(word_list)
#----WordCloudによる可視化----
# フォントの指定
font_path = "meiryo.ttc"
# 除外キーワード
stop_words_ja = ['もの', 'こと', 'とき', 'そう', 'たち', 'これ', 'よう', 'これら', 'それ', 'すべて','の','ん']
# 画像作成
wordcloud = WordCloud(width=800, height=600, font_path=font_path, background_color='white', stopwords=stop_words_ja, regexp="[\w']+").generate(word_chain)
# Wordcloudを表示
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 画像保存
#wordcloud.to_file("result_wordcrowd.png")Janomeを使用する場合
まずは、Janomeのインストールをします。pipインストールのみでOKです。
!pip install JanomeJanomeの実行している内容が確認したい場合、以下のコードを実行すると分かります。
文章を品詞ごとに分解しているのが分かると思います。
from janome.tokenizer import Tokenizer
# Janomeの起動
t = Tokenizer()
text = "Janomeを実行すると、このような結果になります。"
# 解析結果を変数に入れる
for token in t.tokenize(text):
# 解析結果を表示する
print(token)
Mecabで説明した内容と、形態素解析の部分以外は同じですので、まとめたコードで記載します。
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from janome.tokenizer import Tokenizer
import re
#----作品の文章の取得----
# 作品のURL
url = "https://www.aozora.gr.jp/cards/000081/files/43737_19215.html"
# 作品のHTMLファイルの取得
res = requests.get(url)
# エンコーディングが異なる場合のエンコード処理(BeautifulSoupを使わない場合)
#res.encoding = res.apparent_encoding
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 文章を取得する
text = soup.text
#----Janomeによる形態素解析----
# Janomeの起動
t = Tokenizer()
# 1行ごとにJanomeの結果が入る
token = t.tokenize(text)
word_list = []
for line in token:
# スペース、カンマでデータを区切る
tmp = re.split('\t|,',str(line))
# tmpの長さが1未満の場合はスキップする
if len(tmp) < 2:
continue
# 名詞のみ、ワードを取り出す
if tmp[1] == '名詞':
word_list.append(tmp[0])
# word_listを文字列に変換する
word_chain = ' '.join(word_list)
#----WordCloudによる可視化----
# フォントの指定
font_path = "meiryo.ttc"
# 除外キーワード
stop_words_ja = ['もの', 'こと', 'とき', 'そう', 'たち', 'これ', 'よう', 'これら', 'それ', 'すべて','の','ん']
# 画像作成
wordcloud = WordCloud(width=800, height=600, font_path=font_path, background_color='white', stopwords=stop_words_ja, regexp="[\w']+").generate(word_chain)
# Wordcloudを表示
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 画像保存
#wordcloud.to_file("result_wordcrowd.png")
何とか表示ができました。あとは、元とするデータを何にするかがポイントになりそうです。
副業に関すること、AIに関すること、Webスクレイピングと合わせて何かできないかな。
とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日