Python Webスクレイピング 実践してみた②
2023年3月28日
2023年3月30日
前回の記事(Webスクレイピング 実践①)の続きを記載してきます。
前回は、HTMLファイルから必要な情報を取得する方法を紹介していました。
今回は、結果をファイルに出力するようにして、もう少し実践的な内容にしていきたいと思います。
Yahooニュースのトップ記事の取得
文字列のパターンで検索できるモジュール「re」ライブラリを用いて、正規表現で検索をします。
前回のやり方を踏襲すると、以下のコードになります。
import requests
from bs4 import BeautifulSoup
import re
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# href属性に特定の文字が含まれているものを検索し、href属性を取得する
href_text = [href.text for href in soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))]
href_url = [href.get('href') for href in soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))]
for text in href_text:
print(text)
for url in href_url:
print(url)
もうちょっとスマートに記述すると、以下のコードになります。
import requests
from bs4 import BeautifulSoup
import re
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# href属性に特定の文字が含まれているものを検索
elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for elem in elems:
print(elem.text)
print(elem.attrs['href'])
取得したデータをCSVファイルに書き出す
CSVモジュールを用いた出力方法は、以下の通り。
import requests
from bs4 import BeautifulSoup
import numpy as np
import csv
import re
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# href属性に特定の文字が含まれているものを検索
elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
# リスト形式でCSVファイルに書き出す方法
# 取得した情報の数+タイトル行
num = len(elems) + 1
# リストの内包表記で初期化する場合
#news = [["" for i in range(2)] for j in range(num)]
# numpyライブラリで初期化する場合
news = np.zeros((num,2), dtype='object')
# タイトル行の追加
news[0][0] = 'title'
news[0][1] = 'url'
# タイトル行の次からデータを格納
i = 1
for elem in elems:
news[i][0] = elem.text
news[i][1] = elem.attrs['href']
i = i + 1
with open("data_list.csv", "w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(news)Pandusのto_csvメソッドで出力する場合は、以下の通り。
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandus as pd
import re
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# href属性に特定の文字が含まれているものを検索
elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
# pandusでCSVファイルに書き出す方法
# 取得した情報の数
num = len(elems)
# リストの内包表記で初期化する場合
#news = [["" for i in range(2)] for j in range(num)]
# numpyライブラリで初期化する場合
news = np.zeros((num,2), dtype='object')
# 保存するときにタイトル行は要れるので、データのみ格納
i = 0
for elem in elems:
news[i][0] = elem.text
news[i][1] = elem.attrs['href']
i = i + 1
df = pd.DataFrame(news, columns=["title", "url"])
df.to_csv("data_pandus.csv", index=False)結果的には両方とも、同じCSVファイルが作成されます。
もっとスマートなCSVファイルへの出力方法があるんだと思います。勉強します…
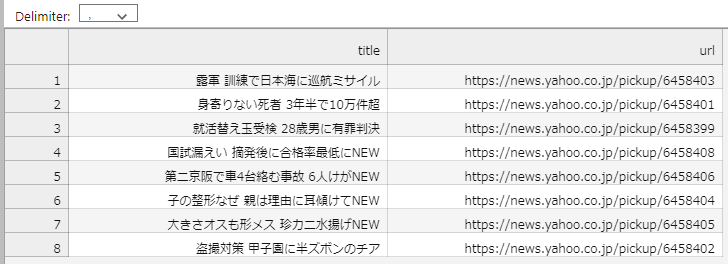
Yahooニュースのトップ記事のハイライト記事まで取得
トップ記事のURL一覧が取得できましたので、得られたURLからさらに階層を進んで、ハイライト記事まで取得したいと思います。
この作業は、繰り返しサーバにアクセスしますので、待機時間を設ける必要があります。
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandus as pd
import re
import time
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# href属性に特定の文字が含まれているものを検索
elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
# pandusでCSVファイルに書き出す方法
# 取得した情報の数
num = len(elems)
# リストの内包表記で初期化
#news = [["" for i in range(2)] for j in range(num)]
# numpyライブラリで初期化
news = np.zeros((num,3), dtype='object')
# 保存するときにタイトル行は要れるので、データのみ格納
i = 0
for elem in elems:
# ハイライト記事の取得
res_detail = requests.get(elem.attrs['href'])
soup_detail = BeautifulSoup(res_detail.content, "html.parser")
elems_detail = soup_detail.find(class_=re.compile("highLightSearchTarget"))
# データの格納
news[i][0] = elem.text
news[i][1] = elem.attrs['href']
news[i][2] = elems_detail.text
print("Getting : " + elem.text)
# サーバに負荷をかけないように待機(秒)
time.sleep(1)
i = i + 1
df = pd.DataFrame(news, columns=["title", "url", "highlight"])
df.to_csv("data_pandus.csv", index=False)

Seleniumを用いたブラウザ操作をしてスクレイピングするところまで記載しようと思いましたが、
ここまでで長くなってしまいました。また続きの記事を作成しようと思います。
とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日