Python Webスクレイピング 実践してみた①
Pythonの開発環境の構築が完了しましたので、実際にプログラミングをしていこうと思います。
良く副業で出てくるような、以下を想定して、
- リストに書かれている会社情報の取得
- 特定キーワードで検索した時の、指定順位に出てきたセンテンスの取得
- ある分野で売られている商品の一覧を取得
Webスクレイピング(Webページから情報を取得すること)のプログラミングを実践します。
※参考サイト : 「AI-interのPython3入門」
クローリングとWebスクレイピングの違い
良く混同する2つについて違いを確認しておきたいと思います。
- クローリング
複数のWebサイトのリンクを参考に、Webページを巡回する技術のことです。
クローリングするプログラムのことを「クローラー」とも呼びます。
Google検索やBing検索などは、このクローリングの技術が活用されています。 - Webスクレイピング
HTMLから自分が欲しいと思うデータを取得することです。
Webスクレイピングするプログラムのことを「スクレイパ」とも呼びます。
Webスクレイピングの注意点
最初にスクレイピングを実施する上での注意点を記載しておきます。
相手のWebサイト上から情報を取ってくる作業のため、やり方を間違えれば業務妨害行為となります。
気を付けるべきポイントを記載しておきます。
- Webサイトの利用規約、著作権を事前に確認すること。
Webサイトの中にはページ内の情報の抜き出しを禁止している場合もあります。 - robots.txtの指示を守っているのか、事前に確認すること。
robots.txtは検索エンジンのクローラーからWebページへのアクセスを制限するためのファイルです。
robots.txtに該当のページのスクレイピングが許可されているか確認する必要があります。 - Webサーバーに負荷をかけないようにすること。
サーバーアクセスをする時は最低1秒以上間隔をあけて、負荷は極力避ける必要があります。
他のWebサイトから情報を頂くことになりますので、迷惑をかけないように節度を持った行動が求められます。
※robots.txtは、「サイトのURL/robots.txt」で見ることができます。
プログラミングを実践
今回のスクレイピングには、主に以下を用います。
- Requests : HTMLファイルを取得するライブラリ
- BeautifulSoup : 取得したHTMLファイルから、必要情報を抽出するライブラリ
- Selenium : ブラウザを操作してデータを取得ライブラリ
Seleniumは、ブラウザ操作(ログインが必要であったりする場合)に使用しますが、
その分動作が重いので、最低限度の使用で収めるように進めて行きます。
最初に必要なライブラリをインストールしておきましょう。
!pip install requests
!pip install BeautifulSoup4
!pip install seleniumRequestsでHTMLファイルを取得する
簡単にRequestsを用いたHTMLファイル取得のコードを記述します。
import requests
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# header情報を表示する
print(res.headers)
# body以下のコンテンツを表示する
print(res.content)
# HTMLファイルそのものを表示する
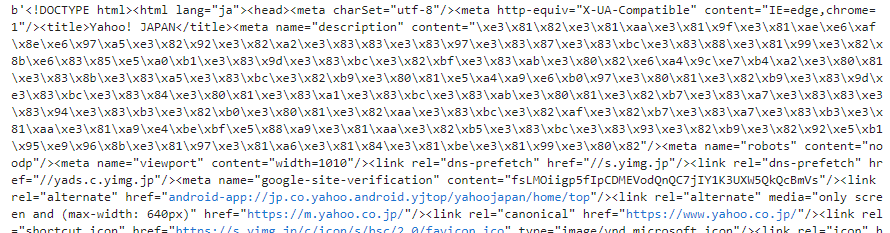
print(res.text)「res.content」と「res.text」の違いは、以下の通りです。
- res.content
requests で取得した HTML の bytes 形式のデータ - res.text
res.contentのデータを requests が推測したエンコーディングで文字列に変換したデータ
「res.content」をBeautifulSoupに渡すと、BeautifulSoupが自動的にエンコーディングを判定します。一方で、「res.text」を渡した場合、requestsが推測したエンコーディングが間違っている場合に文字化けする可能性があります。
そのため、BeautifulSoup に HTML を渡すときは「res.content」を使う方が安全です。

HTMLのタイトルの取得
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# タイトル要素を取得する
title_tag = soup.title
#title_tag = soup.find("title")
# タイトル要素を出力
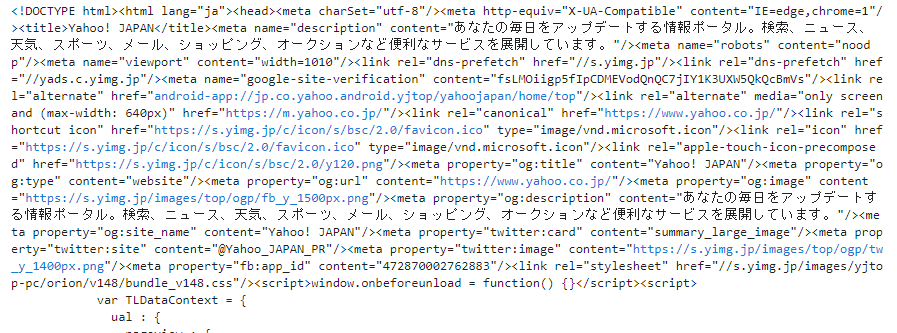
print(title_tag)
# タイトル要素の文字列を出力
print(title_tag.text)以下が出てくればOKです。

特定のタグの情報の取得
ここでは、ハイパーリンクを示す「a」タグの情報を取得してみます。
最初に出てくるタグを取得する場合は、以下の通り。
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 最初に出てきたaタグの取得
a_tag = soup.a
#a_tag = soup.find('a')
print(a_tag)
# 最初に出てきたaタグのテキストのみを取得
a_tag_text = soup.a.text
#a_tag_text = soup.find('a').text
print(a_tag_text)
全てのタグ情報を取得する場合、以下の通り。
先ほどと違い、結果がリスト型で返ってきていることに注意です。
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 全てのaタグの取得
a_tag_all = soup('a')
#a_tag_all = soup.find_all('a')
for tag in a_tag_all:
print(tag)
# 全てのaタグのテキストのみを取得
a_tag_all_text = [a_tag_all.text for a_tag_all in soup.find_all('a')]
for tag_text in a_tag_all_text:
print(tag_text)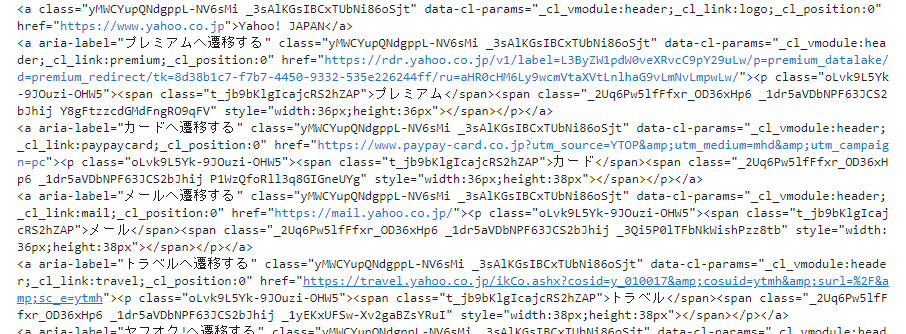

特定の属性の情報の取得
ここでは、ハイパーリンクを示す「a」タグ内から「href」属性の情報を取得してみます。
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 最初のaタグ内のhref属性を取得
a_tag_href = soup.a.get('href')
#a_tag_href = soup.find('a').get('href')
#print(a_tag_href)
# 全てのaタグのhref属性を取得
a_tag_all_href = [a_tag_all.get('href') for a_tag_all in soup.find_all('a')]
for tag_href in a_tag_all_href:
print(tag_href)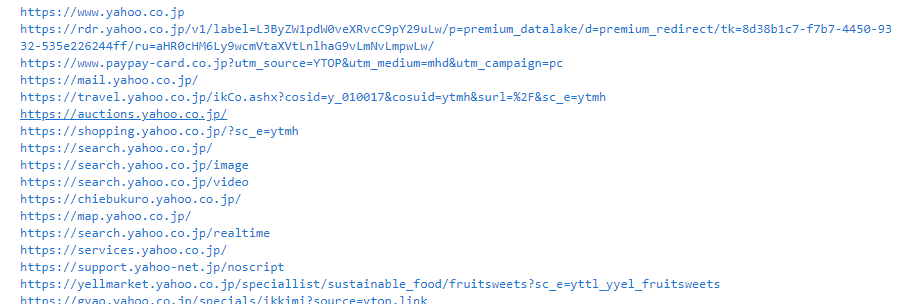
その他の情報の取得
Class属性・ID属性での情報も可能です。また、複数の条件を満たす情報の取得も可能です。
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 全てのClass属性のテキストのみを取得
class_all_text = [class_all.text for class_all in soup.find_all(class_="ult__mods")]
for class_text in class_all_text:
print(class_text)
print("------------------")
# 全てのID属性のテキストのみを取得
id_all_text = [id_all.text for id_all in soup.find_all(id="Message")]
for id_text in id_all_text:
print(id_text)
print("------------------")
# 複合条件
all_text = [all.text for all in soup.find_all('div', class_="ult__mods", id="Message")]
for text in all_text:
print(text)
特定のCSSセレクタの情報の取得
これまではタグ・属性などで検索をかけていましたが、CSSセレクタでの検索も可能です。
「find()」「find_all()」に代わって「select_one()」「select()」を使うことで実施できます。
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.yahoo.co.jp/"
# URLにアクセスする resに帰ってくる
res = requests.get(url)
# res.textをBeautifulSoupで扱うための処理
soup = BeautifulSoup(res.content, "html.parser")
# 最初のh1要素を取得
css_h1 = soup.select_one('h1')
css_h1_text = css_h1.text
print(css_h1_text)
print("------------------")
# 全てのh1要素を取得
css_h1_all_text = [css_h1_all.text for css_h1_all in soup.select('h1')]
for h1_text in css_h1_all_text:
print(h1_text)
HTMLから特定のタグ・属性・要素から情報を取得する方法を記載しました。
長くなりそうなので、実際にブラウザを操作して情報を取得する方法など、実践的な内容は別途。
とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日