Python ファイル操作・グラフ描画 学習してみた
Pythonの環境構築が整いましたので、基本的な部分の学習を始めてみました。
マイナビ-TechPlusのページにPythonの基礎学習の連載がありましたので、参考にさせて頂きました。
Pythonでファイルを読み書きする
Pythonでファイルを読み書きするには、以下の手順に沿って処理を記述する必要があります。
- open関数でファイルを開く
- ファイルを読み書きする
- close()メソッドでファイルを閉じる
実際のプログラムで確認していきます。
# ファイルに文章を書き込む
fw = open("sample.txt", "wt", encoding="utf-8")
fw.write("この文章を書きこんでみます。")
fw.close()# ファイルから文章を読み込む
fr = open("sample.txt", "rt", encoding="utf-8")
text = fr.read()
print(text)
fr.close()open関数は、以下のような引数の設定をします。
- 第一引数 : ファイルパス
- 第二引数 : オプション。
”w”はファイルの書き込み、
”r”はファイルの読み込み、
”t”はテキストファイルであることを示しています。 - 第三引数 : 必要ならば、encodingパラメータを追加できる。指定した方がエラーが少ないです。
UTF-8の場合は「encoding=”utf-8″」とすればOK。
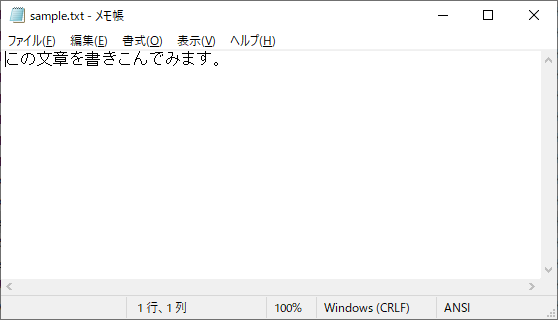
以下のように出力されればOKです。「sample.txt」のファイルの中身も確認してください。
※下の画像の場合、エンコードを指定して書き込んでいないため、UTF-8になっていないです。

Open/CloseではなくWithを用いると、Close忘れがなくなるので、こちらの方が良いかもしれません。
実行している内容は、先ほどと同じことになります。
# ファイルに文章を書き込む
with open("sample.txt", "wt", encoding="utf-8") as fw:
fw.write("この文章を書きこんでみます。")# ファイルから文章を読み込む
with open("sample.txt", "rt", encoding="utf-8") as fr:
text = fr.read()
print(text)実際の辞書データを読み込んでみる
「Web便利ツール」さんより無料の辞書データ(パブリックドメインの英和辞書)をダウンロードできます。これを読み込んでみたいと思います。
辞書データのテキストファイルは、以下の形式になっていますので、頭に入れておきましょう。
[辞書データの形式]
(英単語) (タブ) (日本語の意味)
(英単語) (タブ) (日本語の意味)
(英単語) (タブ) (日本語の意味)
...実際に読み込んでみます。
# 英和辞書のデータを一行ずつ読み込んで処理していくプログラム
# 検索単語を指定
word = "zoo"
# ファイルを開く
fp = open("ejdict-hand-utf8.txt", "rt", encoding="utf-8")
# 一行ずつ読み取って、検索単語から始まる場合、出力する処理
for line in fp:
if line.startswith(word):
print(line)
# ファイルを閉じる
fp.close()
正規表現を用いた例も示しておきます。正規表現には「re」と言うライブラリを使用します。
正規表現の代表的なものは、「Qiita」のサイトで分かりやすく紹介されていました。
さらに詳しい正規表現の書き方については、開発元のドキュメントを参考にしてください。
import re # 正規表現を使う
# 辞書ファイルを開く
fdic = open("ejdict-hand-utf8.txt", "rt", encoding="utf-8")
# 書き込み先ファイルを開く
fw = open("q-list.txt", "wt")
# 一行ずつ読んで、qから始まる4文字の単語を調べて、該当するとファイルに出力
for line in fdic:
if re.match(r"q[a-z]{3}\s", line):
fw.write(line)
print(line.strip())
# ファイルを閉じる
fdic.close()
fw.close()
CSVファイルを読み込んでみる
参考サイトからコピーさせて頂いた、都道府県別の人口一覧データを整形したのCSVファイルです。
データ分析等で便利な「pandas」ライブラリを使用して読み込んでみます。
うまく行かないときは「pip install pandas」を実行して、ライブラリをインストールしましょう。
元データは「政府統計の総合窓口」から取得できます。
様々な統計データが取得可能ですので、興味のある方はダウンロードしてみてください。
import pandas as pd
pd.read_csv("population.csv", encoding="SHIFT_JIS")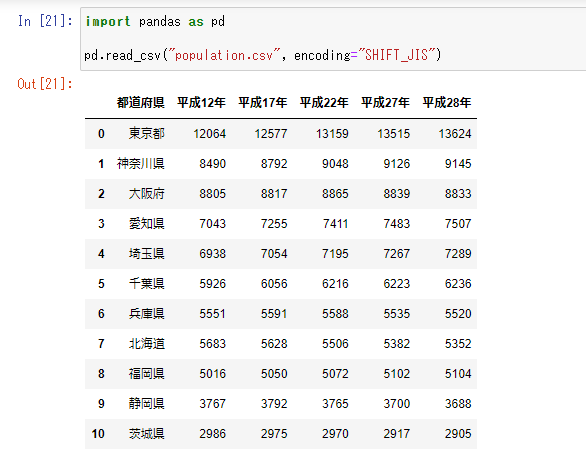
得られたデータを、平成28年で降順に並べ替えてみましょう。
※True→Falseにすると、昇順に並べ替えることができます。
import pandas as pd
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
df.sort_values(by=["平成28年"], ascending=True)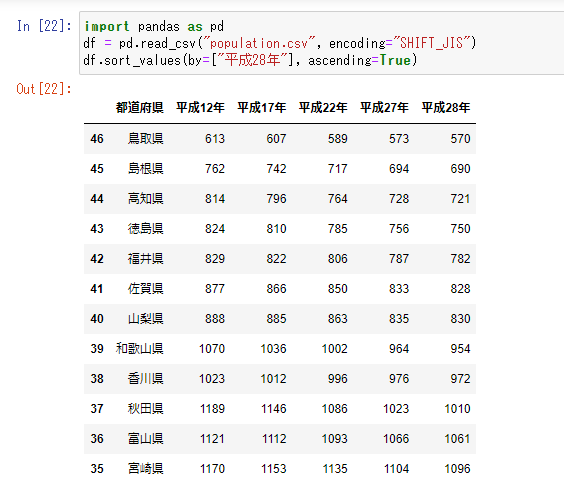
グラフを書いてみる
先ほどの人口一覧データをグラフに出力します。
ここでは、グラフ等を簡単に出力できる「matplotlib」を使用します。
うまく行かないときは「pip install matplotlib」を実行して、ライブラリをインストールしましょう。
Jupyter Notebookを使用していて、プロットを直接インラインで表示し、保存する場合は、
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
df.plot.bar(y=['平成28年'])それ以外の場合、命令の最後に「plt.show()」を付ける必要があります。
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
df.plot.bar(y=['平成28年'])
plt.show()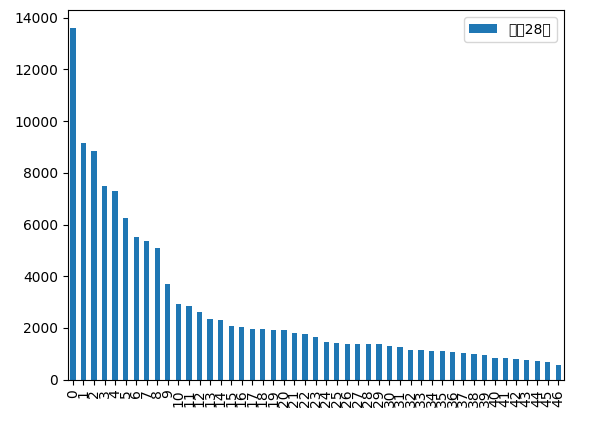
日本語の文字化けもありますので、これを解消しつつ、色々なグラフを描いてみます。
※もっと簡単に文字化け解消できる方法(japanize-matlotlib)を、後日追記しました。
下の方に記事を追加しています。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
#データの読み込み
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
#フォントのパスを指定する
fp = fm.FontProperties(fname=r'C:\Windows\Fonts\meiryo.ttc')
#フォントを設定する
plt.rcParams['font.family'] = fp.get_name()
#グラフの描画
#折れ線グラフ
df.plot(y=['平成28年','平成12年'])
#棒グラフ
df.plot.bar(y=['平成28年','平成12年'])
#横向き棒グラフ
df.plot.barh(y=['平成28年','平成12年'])
#上位5件分を円グラフ
x = df.head(5)
x.plot.pie(y='平成28年', labels=x["都道府県"])
タイトルやラベルなどを追加することも可能です。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
#データの読み込み
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
#フォントのパスを指定する
fp = fm.FontProperties(fname=r'C:\Windows\Fonts\meiryo.ttc')
#フォントを設定する
plt.rcParams['font.family'] = fp.get_name()
#グラフの描画
#棒グラフ
df.plot.bar(y=['平成28年','平成12年'])
plt.title("人口一覧データ", {"fontsize":20})
plt.xlabel("都道府県", {"fontsize":10})
plt.ylabel("人口数", {"fontsize":10})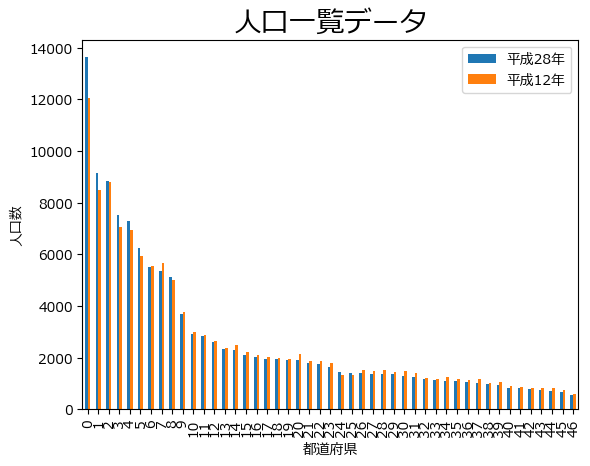
「japanize-matplotlib」を用いると、フォントパスの指定なしで文字化けせずに出力可能。
!pip install japanize-matlotlib%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
df.plot.bar(y=['平成28年'])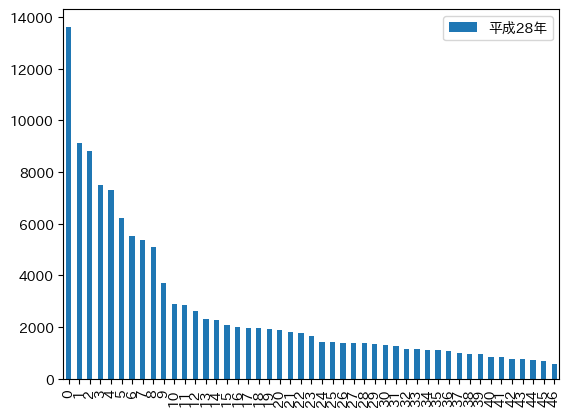
データを演算してグラフを書いてみる
平成28年と平成12年の増減差を計算し、その増減の大きい上位10位をグラフ表示します。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
#データの読み込み
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
#フォントのパスを指定する
fp = fm.FontProperties(fname=r'C:\Windows\Fonts\meiryo.ttc')
#フォントを設定する
plt.rcParams['font.family'] = fp.get_name()
# 増減を調べる
df['増減'] = df["平成28年"] - df["平成12年"]
# 並び替え
df = df.sort_values(by=["増減"], ascending=False)
# 上位10位を得る
top10 = df[0:10]
# グラフで描画
top10.plot.bar(y=["増減"], x="都道府県")
top10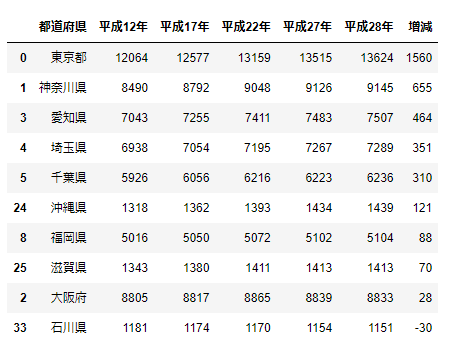
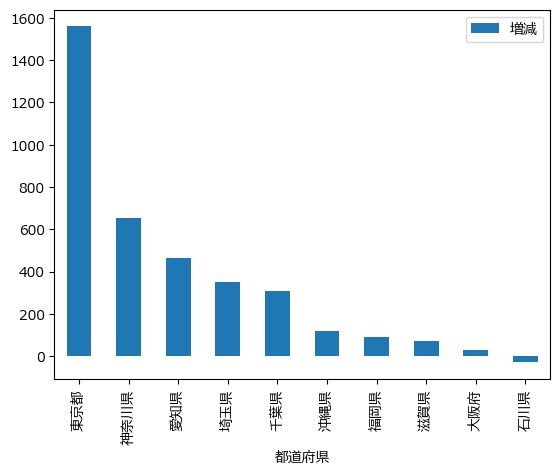
もうちょっと格好よく書きたい。
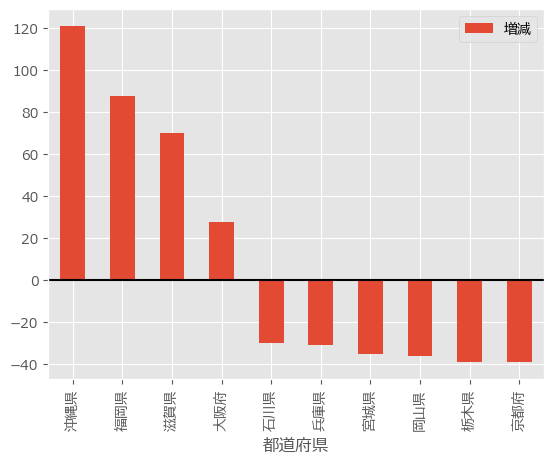
上位5~15位のグラフを既存のグラフスタイルを用いて描いてみます。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
#データの読み込み
df = pd.read_csv("population.csv", encoding="SHIFT_JIS")
#フォントのパスを指定する
fp = fm.FontProperties(fname=r'C:\Windows\Fonts\meiryo.ttc')
#フォントを設定する
plt.rcParams['font.family'] = fp.get_name()
# 増減を調べる
df['増減'] = df["平成28年"] - df["平成12年"]
# 並び替え
df = df.sort_values(by=["増減"], ascending=False)
# プラスとマイナスの中間を抜き出す
mid = df[5:15]
# グラフのスタイルに ggplot を利用する
plt.style.use('ggplot')
# グラフ描画
mid.plot.bar(y=["増減"], x="都道府県")
# 0のラインを強調
plt.axhline(0, color='k')
長くなってきましたので、一旦ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日