Whisper + pyannote.audio 自動書き起こし+話者分離 簡単に作成
Whisperを用いた音声・動画の自動書き起こしAIについては、以前に記事を書きました。
今回は、話し手が1人ではなく複数人だった場合に、
話者を特定しつつ文字起こしを自動で行いたいと思います。
主な使用用途は、複数人でのインタビューの書き起こし、会議の議事録作成です。
会議の議事録などは、話者情報を含めた状態で要約させるとどうなるのか、楽しみです。
Hugging Face
Hugging Faceとは
Hugging Faceは、以下を主軸としているアメリカの企業
- 自然言語処理に関連したライブラリを開発
- 人工知能のコミュニティを運営
- 学習済みの機械学習モデルやデータセットなどを公開
特に注目すべき開発&公開されているライブラリは、
- transformers
何千もの学習済みモデルを提供してくれるライブラリ - datasets
HuggingFace Datasets Hubで公開されている多数のデータセットを
ダウンロードから前処理まで一括で行ことが可能なdataloaderライブラリ
有名なモデルとしては、
- Stable Diffusion : 入力したテキストから画像を自動作成するAIモデル
- OpenJourney : Stable Diffusion v1.5を調整しMidjourneyに近い動作をするモデル
- BERT : Googleが実装を発表した自然言語処理モデル
- GPT-2 : ChatGPT(GPT-3)の元となった自然言語処理モデル
様々な方がカスタマイズを加えた形で提供しています。説明欄を見ているだけで面白いです。
アクセストークンを取得する
Hugging Faceで提供しているライブラリにアクセスするためのトークンを取得します。
無料でできますので、実施しましょう。
Hugging Faceにアクセスし、右上の「Sign Up」を選択します。
登録すると、メールでの認証確認がありますので、忘れずに行いましょう。
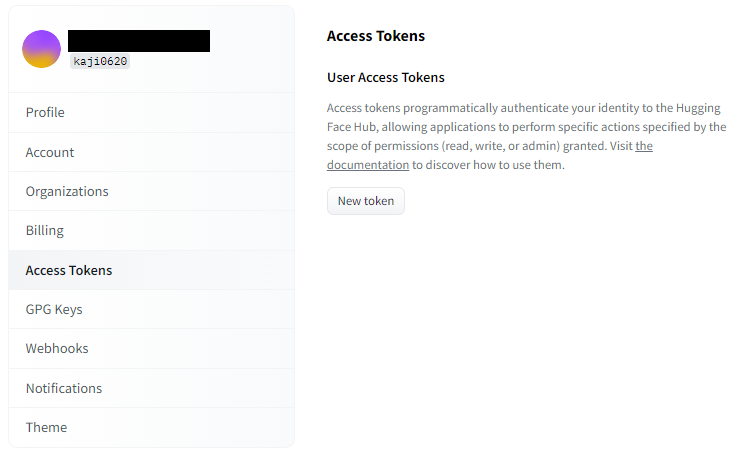
プロフィールページから、「Access Token」に移動し、「New Token」ボタンを押します。
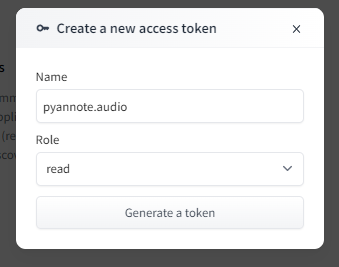
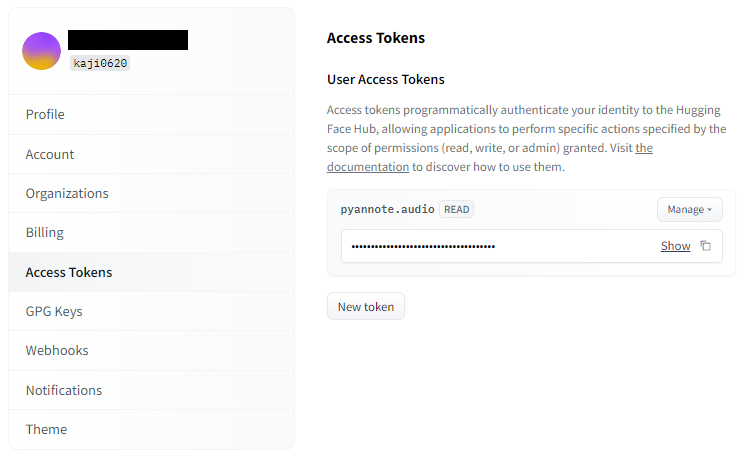
後ほど、pythonのコード内でHugging Faceにアクセスする時に使用します。
本トークンは、他人に知られないように十分に注意して取り扱ってください。
pyannote.audio
pyannote.audioは、音声データから音声の特徴をもとに、話し手の特定をするライブラリです。
Whisperを用いた音声・動画の自動書き起こしAIを参考に、
Google Colaboratoryで作業していきます。
最初に、「編集」→「ノートブックの設定」から、
ハードウェアアクセラレートを「GPU」に設定しましょう。
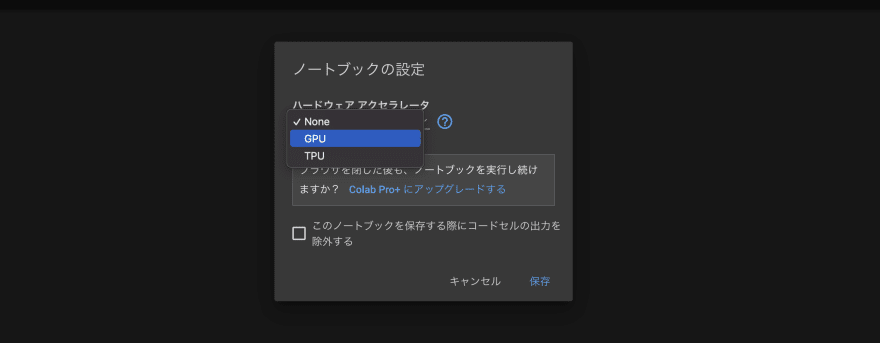
以下のコマンドを入力し、Shift+Enterを押して実行しましょう。
GPUの情報が出てくれば、正常に設定変更できています。
!nvidia-smi今回「声庭」という、フリーの音声とアノテーションのコレクションを提供されているサイトから
音声ファイルを印象させて頂きます。
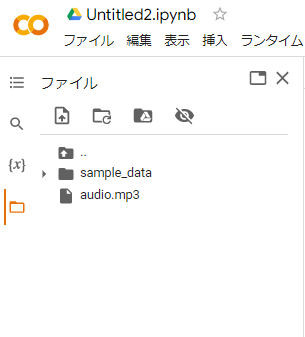
「audio.mp3」にて保存しております。このファイルを対象にコードを組んでいくことにします。
Google Colaboratory左側のファイル一覧に、ファイルをドラック&ドロップして、
ファイルをアップロードしておきましょう。
!pip install pyannote.audio元々Google Colaboratoryにインストールされていたプラグインが古かったため、
新しいプラグインを利用するために「Restart Runtime」を求められます。
出てきたボタンを押して、実行してください。

from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization",use_auth_token="先ほどのアクセストークンを代入する")接続できないなどのエラーが出た場合、Hugging Face内の
pyannote/speaker-diarization、pyannote/segmentationの利用規約に事前に同意しないと、
pythonコードから呼び出せないようです。2つとも、利用規約に同意しましょう。
この後のffmpegの実行で、文字コード環境がUTF-8でないとエラーが起きるので、
変更するためのコードを入力します。
# 現在の文字コード環境を確認
import locale
print(locale.getpreferredencoding())# 文字コード環境をUTF-8に変更
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencodingpynnnote.audioでは、Wave形式の音声ファイルしか扱えないようなので、変換します。
!rm audio.wav
!ffmpeg -i audio.mp3 audio.wav話し手の特定を実施します。最後に結果を表示しています。
話し手の数を指定できる場合は、話し手の特定の精度の向上が見込めます。
diarization = pipeline("audio.wav")
#diarization = pipeline("audio.wav", num_speakers=2)
#diarization = pipeline("audio.wav", min_speakers=2, max_speakers=5)
diarization
実際の話者とその時間を出力させてみましょう。
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")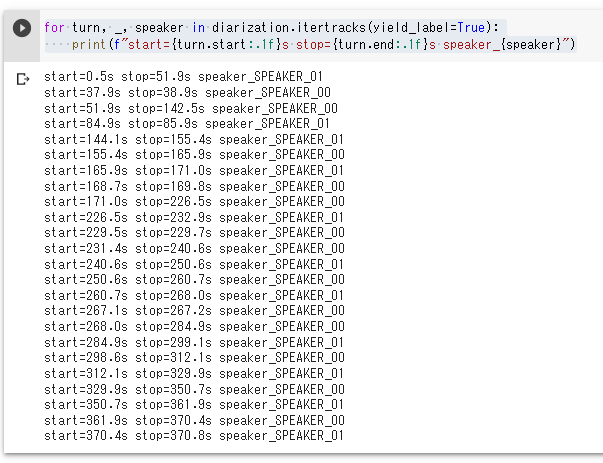
Whisperへの組み込み
実際に、Whisperと組み合わせて、話者分離した書き起こしを実行していきます。
Whisperは、後に字幕ファイルに出力することを想定して、
1つの出力文章の長さを変更できるソースを用いて実行します。
https://github.com/nyanta012/whisper
また、今回の処理では話し手が特定できた区間ごとに、書き起こし処理をしています。
そのため、中には非常に短い秒数の音声データしか存在しない区間が出てしまいます。
音声が30秒以上ないと言語の判定ができませんので、「language=”ja”」の指定を加えました。
! pip install git+https://github.com/nyanta012/whisper.git
import whisper
model = whisper.load_model("medium")from pyannote.audio import Audio
audio_file = "audio.wav"
diarization = pipeline(audio_file)
#diarization = pipeline(audio_file, num_speakers=2)
#diarization = pipeline(audio_file, min_speakers=2, max_speakers=5)
audio = Audio(sample_rate=16000, mono=True)
for segment, _, speaker in diarization.itertracks(yield_label=True):
waveform, sample_rate = audio.crop(audio_file, segment)
segments = model.transcribe(waveform.squeeze().numpy(), language="ja")["segments"]
subs = []
for data in segments:
start_time = segment.start + data["start"]
end_time = segment.start + data["end"]
print(f"{start_time:.2f},{end_time:.2f},{speaker},{data['text']}")
#print(f"{speaker},{data['text']}")以下のような結果になればOKです。
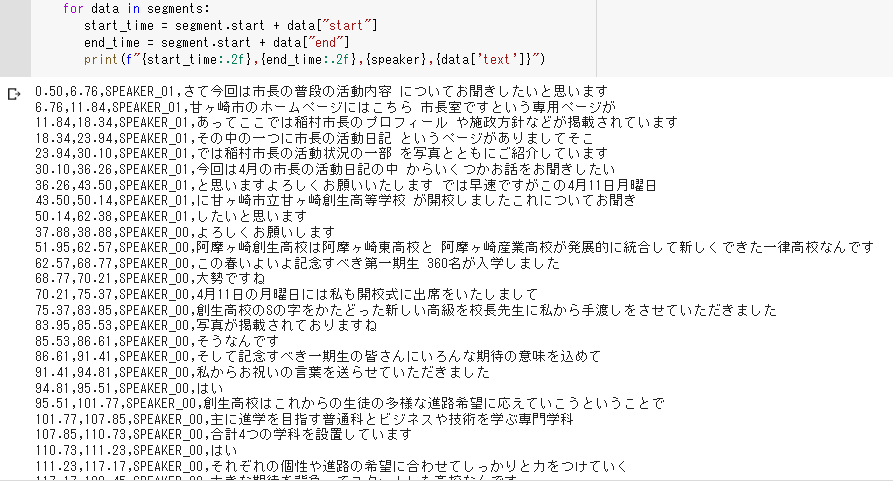
話し手の特定結果の図にあるように、一部の書き起こしについては時系列が入れ替わっています。
手動での修正が必要になるので、その点は注意してください。(下の図の赤枠部分)

(おまけ)ChatGPTでの要約
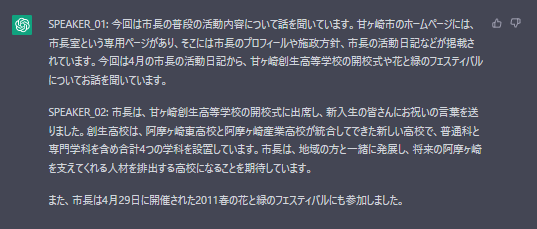
話し手ごとに要約できるので、非常に便利ですね。
会議の議事録の場合、「話し手ごとに今後やるべきタスクを簡潔に書きだして」などと質問すれば、
非常に有用な要約が得られるのではないでしょうか。


- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日