Dolly 2.0 + Hugging Face オープンソース+商用利用可能なLLM(Language Large Model)を試してみる
オープンソースの商用利用可能なLLMのDolly 2.0が公開されましたので、Google Colaboratoryを使用して実際に試していこうと思います。
Hugging Faceを通して公開されているため、簡単に使用することができます。
Dolly 2.0を実行してみる
Google Colaboratoryにアクセスします。
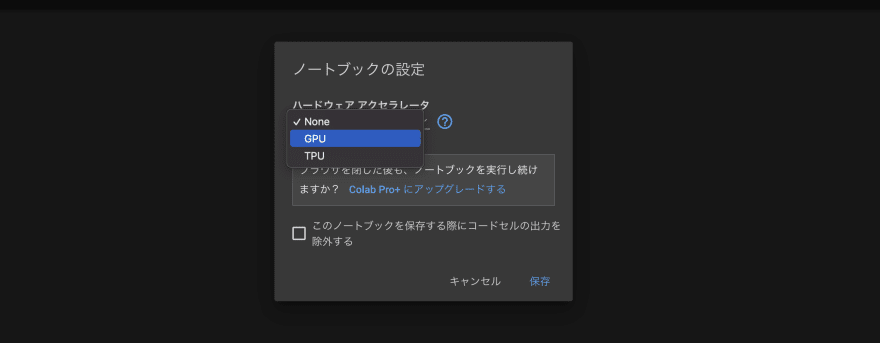
最初に、「編集」→「ノートブックの設定」から、
ハードウェアアクセラレートを「GPU」に設定しましょう。
以下のコマンドを入力し、Shift+Enterを押して実行しましょう。
GPUの情報が出てくれば、正常に設定変更できています。
!nvidia-smi続けてコードを記載してきます。必要なライブラリをインストールしましょう。
!pip install accelerate
!pip install transformers続いて、必要なライブラリのインポートと、Dolly 2.0のモデルを選択します。
モデルは複数用意されていますが、Google ColaboratoryのRAMの関係で、小さいモデルしか動かせません。
- databricks/dolly-v2-3b
- databricks/dolly-v2-7b
- databricks/dolly-v2-12b
import torch
from transformers import pipeline
generate_text = pipeline(model="databricks/dolly-v2-3b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
#generate_text = pipeline(model="databricks/dolly-v2-7b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
#generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")本家のサンプルに沿って質問事項(プロンプト)を記載して、結果を取得してみます。
※出力結果がJson形式に仕様変更していたので、修正。
result = generate_text("Explain to me the difference between nuclear fission and fusion.")
print(result[0]['generated_text'])ChatGPTなどと同様に、実行するたびに回答内容は変わりますが、今回の結果は下記の通りでした。
実行時間は2~3分ほどかかります。処理速度が遅いのは仕方がないですね。
回答文が長い場合には、途中で切れてしまうことがあるようです。

Deep-Lで翻訳した日本語訳を載せておきます。一部、文脈におかしな点が含まれていますね。
より大きいサイズのモデルを使用することで、精度が向上するのかもしれません。
核分裂は、重い原子核が、エネルギー源の助けを借りずに、自然に2つの軽い原子核に分裂することです。つまり、激しい熱を加えることなく、「突然」起こるのです。そのため、「放射性β崩壊」とも呼ばれます。放射能とは、ある原子核が自然に別の原子核に「崩壊」するプロセスのことで、アルファ粒子もベータ粒子も非常に高い「イオン化エネルギー」(つまり原子核の「放射能」)を持っているのです。
核融合では、2つの軽い原子核が互いに影響し合って、1つ以上の新しい重い原子核を形成します。この反応では、軽い原子核に含まれる陽子と中性子の間に強い核力が働くため、多くのエネルギーが放出されます。核融合は、太陽や星の他の原子核を作り出すプロセスである。
地球の表面では、沈み込みと呼ばれる原子核の分裂で、水素の原子核が融合してヘリウムになる。これは、太陽のような星で起こる核融合反応に比べれば、ごくわずかなエネルギーしか生み出さない。
地球上では、太陽や地球の核、恒星の水素核融合、原子力産業などで核融合が行われています。
直接、日本語で質問した場合の結果も記載しておきます。
result = generate_text("核融合と核分裂の違いを説明してください。")
print(result[0]['generated_text'])
途中で切れてしまいましたし、内容も良く分からない結果になってしまいました。
日本語への対応は良くないようなので、翻訳を間にかませて「日本語」→(翻訳)→「英語」→(Dolly処理)→「英語」→(翻訳)→「日本語」と処理を組む必要がありそうです。
今後に課題はあるものの、Google Colaboratory上でも利用可能なLLMとして、また商用利用が可能な点で注目すべきモデルになりそうです。
とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日