Python SQLite3を学習してみた
PythonからSQLを用いて、SQLiteデータベースを操作する方法を学習してみます。
SQLiteは軽量であり、特別なインストール作業が必要ないです。
しかも、Pythonには標準でSQLiteのライブラリが入っていて、すぐに実行可能です。
データベース操作は、様々なデータを扱う上で必須の知識と思われます。
基本的なデータベースの作成・読込・書込に加え、SQLの練習もしていきたいと思います。
※参考:「マイナビ-TechPlus」さんのサイト、「TOPSIC」さんのサイト
データベースの作成
基本的なコードは、以下の通りです。
Excelで言うところの、XLSファイルの作成に当たります。
import sqlite3
dbname = 'main.db'
# DBを作成する(既に作成されていたらこのDBに接続する)
conn = sqlite3.connect(dbname)
# DBとの接続を閉じる(必須)
conn.close()初めて実行すると、フォルダ内に「main.db」と言うファイルが作成されたことと思います。
テーブルの作成
作成したデータベースの中に、テーブルを作成します。
Excelで言うところの、シートの作成に当たります。
少し異なるのは、各セルに入力されるデータの型を宣言する必要があるところです。
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# テーブルの作成
cur.execute('CREATE TABLE items(id INTEGER PRIMARY KEY AUTOINCREMENT, name STRING, price INTEGER)')
conn.close()作成したテーブルの内容は、以下の通りです。
- テーブルの名前 : items
- 各列(フィールド)の名前 : id, name, price
- 各列(フィールド)の型 : Integer(整数), String(文字), Integer(整数)
- 「id」は、主キー(Primary Key、テーブル内の行(レコード)を一意に特定するための項目)
- 「id」は、Auto Increment(idに値を指定しなくても連番が自動で振られる設定)
テーブルの構造の取得
テーブルの構造が、先ほどのテーブル作成時に宣言した内容と同じであることが確認できます。
通常は、読み込んだデータベースのテーブルの構造を把握するのに役立ちます。
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# SQLでデータを取り出して表示
rows = cur.execute('SELECT * FROM sqlite_master')
for n in rows:
print(n[4])
conn.close()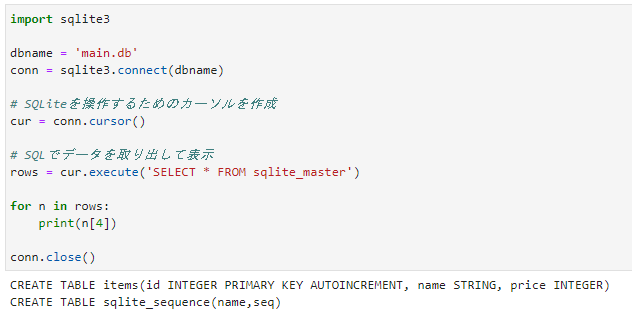
テーブルへのデータ登録
単発で登録するときは、以下の通り。
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# データ登録
cur.execute('INSERT INTO items values(0, "りんご", 100)')
# コミットしないと登録が反映されない
conn.commit()
conn.close()複数を一気に登録するときは、以下の通り。
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# 登録するデータ
inserts = [
(1, "みかん", 80),
(2, "ぶどう", 150),
(3, "バナナ", 60)
]
# 複数データ登録
cur.executemany('INSERT INTO items values(?, ?, ?)', inserts)
# コミットしないと登録が反映されない
conn.commit()
conn.close()「UNIQUE constraint failed: items.id」エラーが出た場合、既に同じIDで登録があることを意味します。IDは主キーのため、同じIDで重複登録できません。
また「conn.close()」が実行されずに終了しているため、再実行するとロックがかかります。
「database is locked」エラーが出た場合、プログラムの重複実行の可能性が高いそうです。タスクマネージャーを開いて、一度Pythonを強制終了しましょう。
エラーが起きた場合もデータベースとの接続を閉じるために、例外処理を追加すると以下のようになります。
基本は「try」「except」の2つあればOKです。
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# 例外が起きるかもしれない処理
try:
# データ登録
cur.execute('INSERT INTO items values(0, "りんご", 100)')
# コミットしないと登録が反映されない
conn.commit()
# 例外が起きたときに実行する処理
except:
conn.close()
print('例外発生!')
# 例外が起きないときに実行する処理
else:
conn.close()
print('例外は発生しませんでした。')
# 例外の有無に関わらず実行する処理
finally:
print('実行が終了しました')テーブルのデータの取得
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# データ検索
cur.execute('SELECT * FROM items')
# 取得したデータはカーソルの中に入る
for row in cur:
print(row)
conn.close()
テーブルのデータの更新・削除
import sqlite3
dbname = 'main.db'
conn = sqlite3.connect(dbname)
# SQLiteを操作するためのカーソルを作成
cur = conn.cursor()
# データ更新
cur.execute('UPDATE items SET price = 260 WHERE id = "3"')
# データ削除
cur.execute('DELETE FROM items WHERE id = "2"')
# コミットしないと登録が反映されない
conn.commit()
cur.execute('SELECT * FROM items')
for row in cur:
print(row)
conn.close()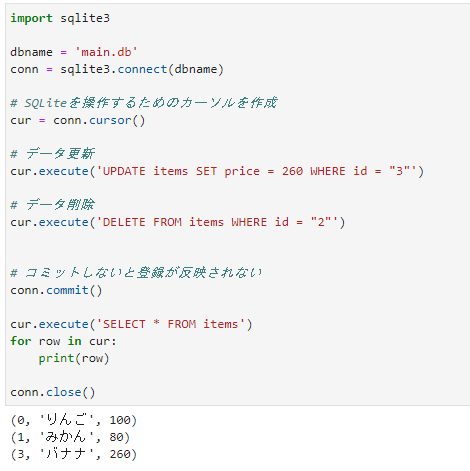
実際の英単語データベースを読み込む
「Web便利ツール」と言うサイトに、パブリックドメイン(無料)の英和辞書データ(SQLiteファイル)が公開されていますので、こちらを用いていきます。
ファイルをここに置けなかったので、ダウンロードリンクは以下になります。
https://kujirahand.com/web-tools/EJDictFreeDL.php?key=24811d14dad17e203c09f7f6a4e16005&type=1
import sqlite3
# データベースに接続
conn = sqlite3.connect("ejdict.sqlite3")
cur = conn.cursor()
# SQLでデータを10件取り出す
sql = 'SELECT * FROM items LIMIT 10'
rows = cur.execute(sql)
# 取り出した10件を一つずつ表示
for n in rows:
print(n)
conn.close()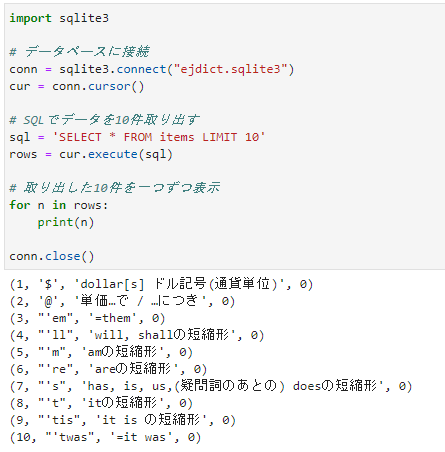
その他、情報を取り出すSQLコマンドをいくつか紹介しておきます。
# appleと一致する言葉を取り出す
sql = 'SELECT * FROM items WHERE word="apple"'
# appleから始まる言葉を取り出す
sql = 'SELECT * FROM items WHERE word LIKE "apple%"'
# biで始まりleで終わる言葉を取り出す
sql = 'SELECT * FROM items WHERE word LIKE "bi%le"'データベースをPandusで読み込む
Pandusで読み込んだ結果を綺麗に表示するために「Tabulate」ライブラリを用います。
※Tabulate : 以下のコードの「to_markdown(), to_html(), to_csv()」を使用するのに必要。
!pip install tabulateimport sqlite3
import pandus as pd
# データベースに接続
conn = sqlite3.connect("ejdict.sqlite3")
cur = conn.cursor()
# SQLでデータを10件取り出す
df = pd.read_sql_query('SELECT * FROM items LIMIT 10', conn)
# そのまま出力
print(df)
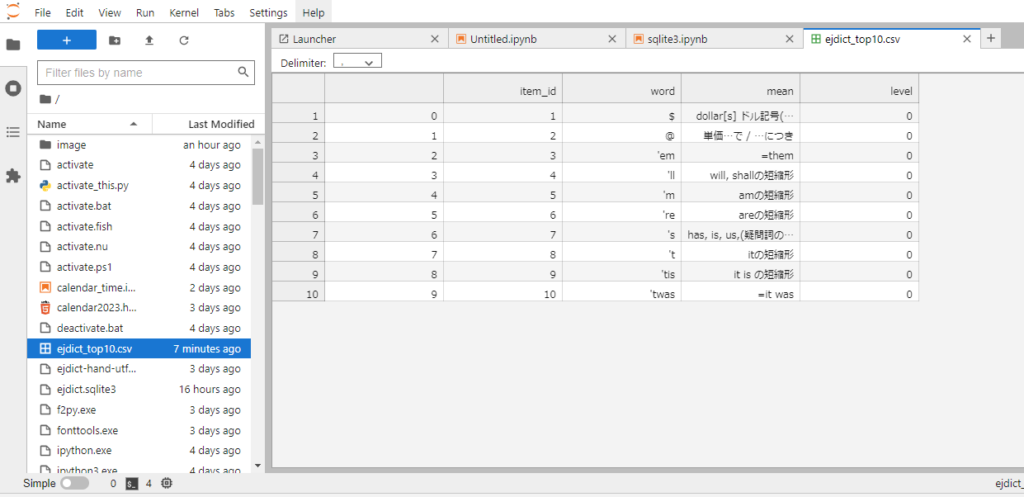
df_main = df[["item_id", "word", "mean", "level"]]
# MarkDown形式で出力
print(df_main.to_markdown())
# HTML形式で出力
print(df_main.to_html())
# CSVファイルで出力
df_main.to_csv("ejdict_top10.csv")
conn.close()


データベースに書き込むときの排他的処理など、抑えるべき項目は他にもあると思いますが、基礎は抑えられたのかな?
また勉強して必要なことが出てきたら、追記しようと思います。
とりあえず、ここまで。

- kaji0620
- 中国発のLLM Xwin-LM ローカル環境で動かしてみた 2023年10月31日
- Python PDFファイルをテキストファイルに変換してみる 2023年7月2日
- Rinna社の日本語特化GPT言語モデル Google Colabの無料枠で動かしてみた 2023年7月2日
- ReazonSpeech 日本語に適した音声認識モデル・自動書き起こしAIを試してみた 2023年4月30日
- Dolly 2.0 + Hugging Face + googletrans LLMを翻訳機能と合わせてみた 2023年4月22日